KV数据的分区
按key的范围分区
按照key的范围进行分区,可以由数据库自动分配,也可以由管理员手动指定。在分区内部,可以按照一定顺序进行排序,进行scan的范围查询会非常方便。
缺点就是容易形成热点,如果key是时间的话,那么一段时间内只会写入其中的某一个分区,造成写入过载。
按key的hash分区
为了避免数据倾斜和热点,许多分布式存储通过key的hash确定分区。但是使用了hash之后,则牺牲了范围查询的特性。
一般key的首字段都建议用区分度比较高的,其余字段可以进行范围查询。比如key设计为(user_id, timestamp),则可以检查指定用户在某个时间范围内的记录。
负载倾斜与消除热点
即使按照key做了hash,在极端场景下,某个key也可能发生大量的读写,比如twitter上的明星发推。对于这种场景,可以在key后面加随机值,来分散这个key的写压力。但是带来的成本,就是需要记录哪些key加了随机值,此外需要在读的时候扫描多个key,才能获取完全的记录。
分区与二级索引
按文档的二级索引(document-based)
每个分区只维护自己的二级索引,索引也只会覆盖本分区的文档,它不会关心其他分区的数据。这种索引也被成为本地索引(local index)。
在查询数据库的时候,成本会比较昂贵,需要从所有分区的二级索引中查找记录。这种方法也被成为scatter/gather,即使是并发查询,也需要等待长尾的完成。这种方法被应用在MongoDB、Riak、Cassandra、Elasticsearch等。
按关键词的二级索引(term-based)
如果要构建一个覆盖所有分区的全局索引(global index),索引将按关键词进行分区。相比于本地索引,读取更有效率,因为不需要从所有分区进行收集。但是缺点也同样明显,写入会非常复杂,需要写入文档中包含的所有关键词的分区,将会需要有跨分区的分布式事务。实际中,对索引的更新将是异步的,将会有一定时间的延迟。
分区再平衡
平衡策略
反面案例:hash mod N
如果通过hash(key) mod N的结果来分配分区,但是如果N的数量发生变化的话,将会造成大量的数据迁移,成本过于昂贵。
固定数量的分区
可以在最开始的时候,创建比节点数量多的分区。比如只有10个节点,先创建好1000个分区,后续如果进行扩容的话,直接移动一些分区到新的节点上即可。需要注意的是,选择合适数量的初始分区数,分区数太多会导致额外的管理成本,分区数太少会造成后续再平衡的代价很高。
动态分区
HBase会按照键的范围进行动态创建分区,如果分区太大,会自动split成多个分区。如果分区中的大量数据被删除或者分区太小,会自动和相邻分区进行合并。
每个分区会分配给一个节点,一个节点会管理多个分区。通过动态分区,可以让每个分区的大小限制在比较合理的范围内。
需要注意的是,如果数据库最一开始只有一个分区的话,那么最初的所有读写会全部集中在某一个节点上。所有需要预先分配一批分区,从而避免这种情况。
按节点比例分区
Cassandra采用的策略,是节点数和分区数成正比,每个节点管理相同数量的分区。当数据集增大,每个分区管理的数据也会变多。
当一个新的节点加入集群后,会随机挑选一些分区,将这些分区的一半数据分走。其余的一半仍然留在原处。
请求路由
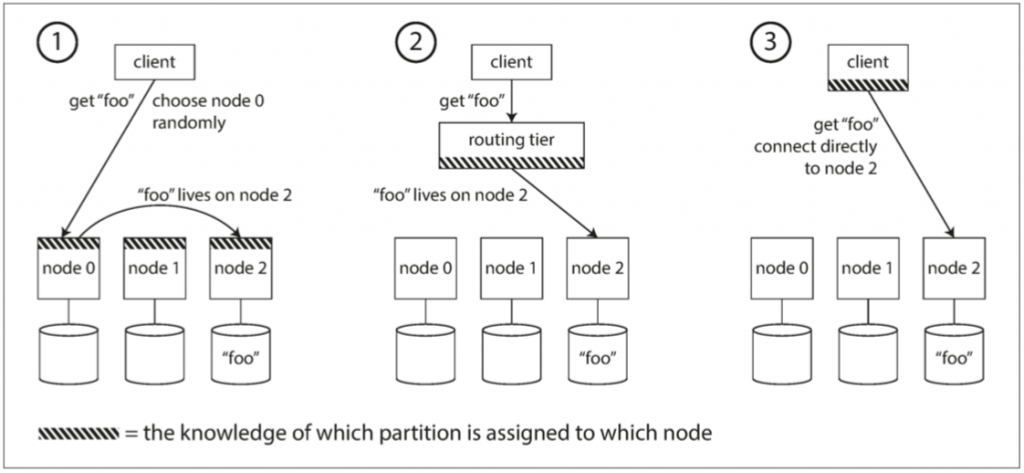
许多分布式数据库会依赖ZooKeeper来跟踪集群元数据。ZooKeeper会维护分区到节点的映射关系,每个节点会在zk上注册自己。路由层可以在zk中订阅这个消息,只要分区有改变或者集群中增删节点,zk就会通知路由层,从而使映射关系保持最新。比如HBase、SolrCloud这样。
Cassandra则通过gossip protocol来传播集群间的变化,请求可以发送给任意节点,该节点会转发给正确的节点,即图中的第一种方法。