事务是将多个读写操作合并成一个逻辑单元,整个事务要么成功,要么失败回滚。有了事务,应用程序的处理就会方便很多,不用特别关注并发、部分出错等问题。
事务的概念
ACID
原子性(Atomicity)
原子性指的是用户的操作,要么全部成功,要么全部回滚,不用担心中途出错结果未知的问题。更准确的定义是:能够在出错时中止事务,丢弃该事务所有写入的能力。
一致性(Consistency)
很多人对一致性存在误解,其实一致性指的是所有的数据需要符合业务规则上的一致,比如在会计系统中,所有的账户需要借贷相抵。但是,这个一致性需要由应用系统来保证,而不是由数据库来保证。如果要保证一致性,首先需要业务逻辑是准确无误的。
隔离性(Isolation)
隔离性指的是并发的事务不会互相影响。每个事务都可以当作自己是数据库中唯一的事务,即使和其他事务一起执行,结果也和逐个执行的效果是一致的。
要实现完全意义上的隔离性,就要做到可序列化(Serializability)。但是这个给性能带来比较大的开销,实际中一般会使用较弱的隔离方式,比如快照隔离(snapshot isolation) 。
持久性(Durability)
持久性指的是,一旦事务提交成功,即使发生硬件故障等问题,结果也不会丢失。比如在单节点数据库中,需要写入到WAL日志中。在带复制的数据库中,持久性意味着数据已经复制到一定数量的节点中。只有这些写入成功,才算是事务提交成功。
单对象和多对象操作
单对象写入
当写入一个单对象时,同样要保证原子性和隔离性,比如写入数据时不会只存储一半,另一个用户不会看到正在更新的值。通过故障恢复日志,可以保证单对象的原子性。通过对象上的锁,保证每次只允许一个线程访问对象,从而实现隔离。
此外对于自增的操作,可以通过CAS(compare-and-set)来实现。这些对单对象的操作,并不是通常意义的事务,也称为轻量级事务。涉及到多个对象的操作,合并为一个逻辑单元,更符合事务的定义。
多对象事务的场景
有一些场景,单对象的操作是不够的,比如:
- 关系数据模型中,外键引用必须正确。
- 文档数据模型中,一次更新多个文档,需要保证多个文档间的同步。
- 在具有二级索引的数据库中,每次更新记录需要更新索引。
弱隔离级别
读已提交(Read Commited)
- 只会读到已提交的数据(没有脏读)
- 只会覆盖已经写入的数据(没有脏写)
脏读(dirty reads)
如果事务能够看到另一个事务正在提交的数据,就是脏读。一方面,因为一个事务会涉及多个对象的写入,脏读可能仅读到部分的更新;另一方面,事务后续有可能会出错回滚,脏读的数据可能不会出现在数据库中。
脏写(dirty writes)
如果有两个事务需要更新同一个对象,后来的写入会覆盖之前的写入,但是只能覆盖已经提交的写入,否则就是脏写。脏写会导致不同事务的写入混淆在一起,导致未知的混乱。
读已提交的实现
可以通过行锁来阻止脏写,在写某一行时需要先获取锁,一直持有直到事务的结束。其他事务则需要等待。
脏读同样可以通过行锁来解决,但是会带来较大的性能损失。所以,实际中大部分数据库的做法是通过读取旧值。事务过程中,会一直保存对象旧的值。
可重复读(Repeatable Read)
不可重复读(nonrepeatable read / read skew)
如果在一个事务中,两次读取的数据不一致,或者存在矛盾,在某些场景下将会带来严重后果:
- 备份 —— 备份的过程会持续很长时间,如果存在不可重复读,不一致的数据将会持久化到备库中。
- 分析查询 —— 一个查询也会持续很长时间,返回不一致结果将会使查询结果无意义。
解决方法 – 快照隔离(snapshot isolation)
快照隔离的思想就是,事务开始的时候给数据库做个快照,事务过程中的所有读取都是从这个快照查询的,即使这个结果已经被另一个事务修改了。
为了实现快照隔离,需要保留一个对象的多个不同的提交版本,即MVCC(multi-version concurrency control)。读已提交,理论上也是可以通过mvcc来实现,只不过只需要保留两个版本就足够了,即已提交的版本和尚未提交的新版本。如果是读已提交的隔离级别,那么mvcc为每个查询使用单独的快照就可以实现。
其他并发写入情况
丢失更新(lost update)
如果应用的操作流程是读取-修改-写入,比如将数据库中的值加一,或者两个人同时修改wiki页面。并发写入时可能会出现丢失更新的问题,即其中一个的更新被丢失,另一个的更新并没有包含之前的内容。有各种解决方案:
- 原子写 —— update counter set value = value + 1 where key = ?
- 显示锁定 —— select for update
- 自动检测 —— 数据库能够检测出丢失更新,并及时中止事务
- CAS – update wiki_pages set content = ‘new’ where content = ‘old’ and id = ?
Write Skew
刚才的情况只涉及到了并发写入相同对象导致的竞争,但是即使是不同对象之间的写入,也会存在竞争,从而导致异常,称为write skew。
导致write skew情况出现,基本都是遵循类似的模式,如下所示。其原因就在于,第三步的执行会修改第一步的查询结果,但是第一步又是执行第三步的先决条件。
- 先SELECT出符合条件的行
- 应用代码根据查询结果判断是否应该继续
- 如果继续,则执行写入,并提交事务
类似的场景会有很多,比如两个人想注册相同的用户名,想预定相同时间段的会议室等等。在这些场景中,select for update是不可行的,因为不会锁住任何的行。要想根本解决这种冲突,可以通过可串行化(Serializable)的隔离级别。
可串行化(Serializable)
可串行化是最严格的隔离级别,可以防止所有可能的竞争情况。
真正的串行执行
- 所有的操作都是单线程上,按顺序依次执行事务。
- 在存储过程中封装事务
- 也可以将数据分区,每个分区内串行,多分区之间可以并行,但是跨分区事务就会比较慢。
两阶段锁定(Two-phase locking)
两阶段锁定要求写入不仅会阻塞其他的写入,还会阻塞读;读取也会阻塞其他的写入。同快照隔离的“读不阻塞写,写不阻塞读”不同。
两阶段锁的实现
锁会存在两种模式,共享模式(shared mode)和独占模式(exclusive mode),具体规则为:
- 如果要读取对象,先以共享模式获取锁,允许多个事务同时持有共享锁。
- 如果要写入对象,以独占模式获取锁,没有其他事务可以同时持有。
- 如果事务先读取再写入,会将共享锁升级为独占锁。
- 事务获取锁后,需要持有到事务结束,再释放持有的锁。
但是这种方式,一方面会有获取释放锁的开销,另一方面,也降低了并发度。此外,可能会更频繁地出现死锁,从而需要不停地重试。
谓词锁(predicate locking)
对于之前提到的预定会议室,实际上并不存在锁定的对象。如果想要通过锁来进行互斥,那么需要锁定的对象就是未来符合条件的记录,即谓词锁(predicate lock)。
如果事务A想要读取匹配条件的记录,需要先获取共享谓词锁。如果其他事务B持有满足条件对象的排他锁,则A需要等待B的事务结束。
如果事务A想要更新记录,需要检查旧值和新值是否匹配已有的谓词锁。如果事务B持有谓词锁,那么A需要等待B事务结束。
间隙锁(next-key locking)
谓词锁的性能是个问题,主要是匹配锁的成本比较高。所以很多实现采用了间隙锁,即锁定索引上的范围。另一个事务更新记录时,一定需要更新相应的索引,那么就会遇到间隙锁,从而阻止冲突的发生,而且成本开销也更低。
可串行化快照隔离(SSI, serializable snapshot isolation)
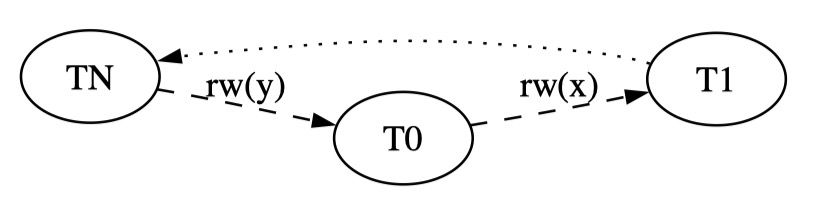
让SI达到串行的效果,只要识别出潜在的无法串行的事务,让这些事务出错重试即可。通过引入multi-version serialization graph (MVSG),然后寻找这样的事务,既是一个 rw-dependency 的 reader、又是一个 rw-dependency 的 writer,就必须中止该事务提交。虽然可能导致误杀,但是检测环的成本太高,所以是可以接受的代价。
下图中,T0事务既是y的writer,又是x的reader,所以有存在环的可能性,需要阻止T0的提交。对于会议室预定的场景,没有实际存在的对象,就需要考虑间隙锁的读写情况。