主从复制
主从模式的工作原理:
- 写请求只能发送给主库,主库会将数据写入本地存储
- 主库写入的同时,会将数据变更(replication log / change stream)发送给所有的从库,从库拉取数据后,按照相同的顺序更新其本地副本
- 查询可以走主库和从库,但是写只能走主库
同步复制与异步复制
| 复制方式 | 优点 | 缺点 |
|---|---|---|
| 同步复制 | 1. 主从库拥有相同的数据 2. 主库失效也可以切换从库 | 1. 响应延迟 2. 可用性,需要等待从库可用 |
| 异步复制 | 1. 即使从库落后,也可以写入 | 1. 主库失效,可能丢失数据 |
处理节点宕机
从库失效
从库崩溃或者失效连接,故障恢复后,从日志中分析出失效前处理的一个事务,从主库获取这一刻之后的所有数据变更。当应用完这些变更后,就赶上了主库。
主库失效
主库失效后,需要做failover。需要将一个从库提升为主库,其他从库需要从新的主库拉取变更。步骤如下:
- 确保主库是失效的
- 选择一个从库作为新的主库
- 重新配置系统以启用新主库,客户端需要将写请求发送给新主库,其他从库需要从新的主库拉取变更。如果老的主库恢复,需要避免脑裂
故障切换也会遇到一些问题:
- 如果是异步复制,那么新主库的数据可能还没有完全赶上老主库。老主库加入集群后,可能会出现冲突的写入
- 出现冲突写入,那么丢弃掉老的写入可能是比较高危的操作
- 需要避免出现脑裂,即同时出现两个主库,需要有一个fencing机制,检测到有两个主库时需要杀掉其中一个
- 需要配置合适的超时时间
复制日志的实现
基于语句的复制(statement-based replication)
主库的每个写入语句都会复制到从库,包括insert、delete、update等,从库解析并执行语句。优点就是相比于行复制,日志会非常紧凑
- 非确定性的函数,再次执行会产生不同的结果,比如rand()函数
- 如果语句使用了自增列,或者是update .. where …这样的语句,必须保证执行顺序完全相同。那么在多个并发事务的场景,可能会存在问题
- 触发器、存储过程、自定义函数等,在不同的副本可能有不同的效果
WAL日志(write-ahead log)
对于覆盖磁盘的B树索引,每次修改都是先写入wal日志,以便崩溃后可以恢复到一致的状态。这些日志可以通过网络发送给从库,从库根据这些日志可以建立完全相同的副本。
PostgreSQL和Oracle都是使用这种复制日志,缺点就是日志非常底层,和存储引擎紧密耦合,对于运维可能是一个挑战。
基于行的复制(row-based replication)
为了避免复制日志和存储引擎紧密耦合,可以基于行的复制,日志中会包含行粒度的信息
- 如果是INSERT,日志中记录该行所有列的新值
- 如果是DELETE,日志中会标识被删除的这行,比如通过主键来标识。如果没有主键,则需要记录所有的旧值
- 如果是UPDATE,日志中会记录这一行的主键,以及所有被更新列的新值
如果是修改多行记录的事务,则日志中会记录多行,并在最后标识事务的提交。MySQL的binlog就是基于行的复制(如果配置是基于行的话)。
这样可以保证日志和存储引擎解耦,可以更容易地向后兼容,主从甚至可以用不同的存储引擎。
对于外部程序来说,这种日志也更容易解析,可以用来做数据变更捕获(change data capture),方便地将数据同步到数据仓库等外部系统。
基于触发器的复制(trigger-based replication)
基于触发器的复制,可能会更加灵活,可以加上业务的规则。但是,这种方式开销比较大,而且会有各种的限制
复制延迟的问题
读取自己的写
用户提交后,应该可以立即看到自己的写入内容。如果是异步复制,可能会出现写入走主库,查询走从库,从而导致用户看不到自己的写。这种情况下,我们需要读写一致性(read-after-write consistency / read-your-writes consistency)。可能的解法有:
- 读用户自己可能修改的内容时,都从主库读。比如在社交网站上,读取自己的资料都是从主库,读取别的用户资料则读从库
- 可以以其他的标准来衡量是否从主库读,比如更新后的一段时间内都从主库读
- 客户端记住上一次更新的时间戳,只有从库更新时间领先于这个时间,才去读从库
- 如果用户从一台设备写,从另一台设备去读,这种方法就不适合了,需要存在一个中心存储
单调读(Monotonic reads)
当用户读取两个从库的时候,可能会出现读取结果的时间倒退。这种可以根据用户ID的hash来选择副本,保证同一个用户只从一个副本去查询。
一致顺序读(consistent prefix reads)
一致顺序读,指的是如果有一系列的写入具有前后因果关系,那么后续任何的读都应该按照这个同样的顺序。解决办法,就是将这些有因果关系的数据写入相同的分区。
多主复制
多主复制的场景
运维多个数据中心
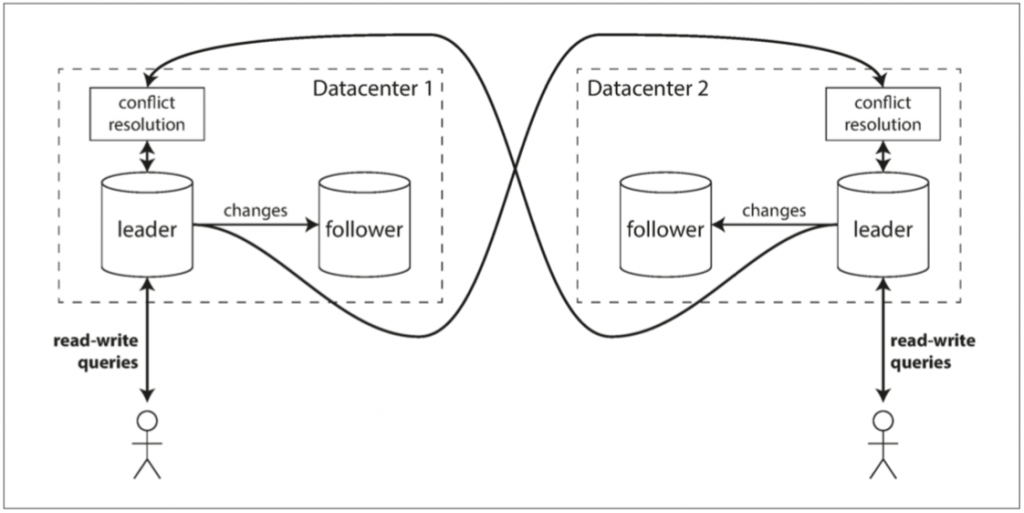
- 性能 —— 写操作只经过本地的数据中心,性能会更好
- 高可用 —— 每个数据中心都是独立于其他数据中心的
- 容忍网络 —— 临时的网络终端并不妨碍正在进行的写入
- 但是需要解决写入冲突的问题
需要离线操作的客户端
需要应用程序在断网后可以继续工作。当断网时,客户端充当临时的主库,当网络连接时进行多主之间的复制。
协同编辑
实时协作编辑的应用,比如在线文档,允许用户同时进行修改。当一个用户修改文档后,应当将本地的修改,并异步复制给服务器和这个文档的其他用户。
写入冲突的解决
避免冲突
如果应用程序可以确保特定用户的写入,都路由到同一个数据中心,由同一个主库来进行管理,那么冲突就不会发生。
趋同至一致状态
在单主的数据库中,如果同一个字段有多次更新,那么最终保留的是由最后一次写入决定的。但是在多主情况下,写入顺序是没有定义的。需要趋同为同一个状态:
- 给每个写入一个ID,保留最高的ID的写入,抛弃其他ID的写入。如果使用时间戳的话,这种技术也被称为LWW(Last write wins),但是容易造成数据丢失。
- 为每个副本分配一个ID,ID高的拥有高优先级,这种方法同样会造成数据丢失。
- 以某种方式合并在一起,比如字符串拼接到一起
- 保留所有的冲突信息,让用户来决定保留的值
自定义冲突解决的逻辑
可以在写的时候进行检测,也可以在读的时候发现冲突,会返回冲突的所有版本,由用户来解决或者自动解决掉。
无主复制
节点故障时的写入
主从模式发生故障,需要作故障切换。但是对于无主模式,不需要做这样的事情,三个副本接受写入,只要有两个副本响应成功,就认为是写入成功了。
当不可用的节点重新上线后,系统中就会同时存在新旧值。因此读的请求也要发给多个节点,通过版本号来确定最新的值。
读修复(read repair)
当客户端读取多个节点的值后,可以检测到旧的值,然后就可以让对应节点写入新值。这种方法适合频繁读取的场景。
Anti-entropy process
一些数据存储会有后台进程来不断检查副本之间的数据差异,并将缺少的数据拷贝到需要的副本。如果没有这种方法,那么读取很少的值将得不到更新。
quorum
如果有n个副本,写入需要w节点成功,读取需要r节点成功。只要w + r > n,则保证读取到的值中有最新值。一般来说,n配置为奇数,w=r配置为(n+1)/2。如果是写少读多的场景,可以配置为w=n且r=1,从而加快查询速度。
检测并发写入
Last write wins
LWW虽然实现了收敛的目的,但是是以持久性为代价的。如果一个key被并发写入,只会有一个值最终写入成功,其他的值都被丢弃掉了。如果是缓存,这种方式还可以接受,但是对于其他场景可能就不太合适了。
因果关系与并发
如果A操作是insert value (x, 1),B操作是update value +1 where key = x,则B操作是依赖于A的完成的,两者具有前后因果关系,否则就是并发的关系。