Autoencoders, GANS AND Diffusion Models
自编码器(Autoencoders)
自编码器的核心目标是学习将输入数据映射到其输出端。这听起来可能像是一项简单的任务,但添加各种约束条件后,就会变得相当困难。例如,你可以限制潜在表示(latent representation)的大小,或者给输入添加噪声并训练网络恢复原始输入。这些约束阻止了自编码器直接简单地将输入复制到输出,从而迫使它学习高效的数据表示方法。所以也可以说编码是这个过程中的“副产品”。
自编码器的组成
40, 27, 25, 36, 81, 57, 10, 73, 19, 68
50, 48, 46, 44, 42, 40, 38, 36, 34, 32, 30, 28, 26, 24, 22, 20, 18, 16, 14
上文的两个序列中,虽然第一个序列更加短,但是没有规律,第二个序列是递减等差数列,更容易被记住。仅需要记住首项、末项、公差即可。将序列识别为等差数列的过程,就是encoder,而将等差数列还原为数字序列的过程,就是decoder。如果encoder不做约束的话,它就会完成记住更短的序列,从而忽略第二个序列中的模式。
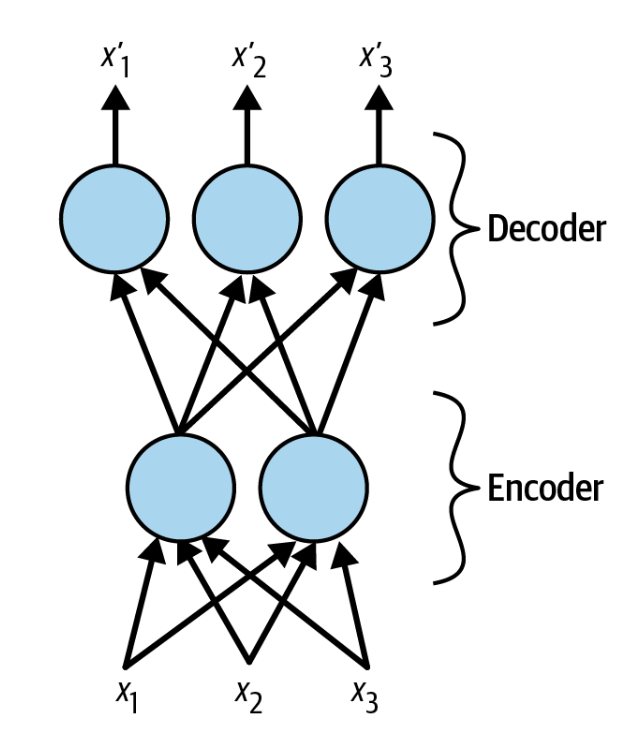
一个自编码器,总会包含两个部分。一个是encoder,也叫识别网络(recognition network),另一个为decoder,也叫生成网络(generative network)。
通过自编码器进行PCA
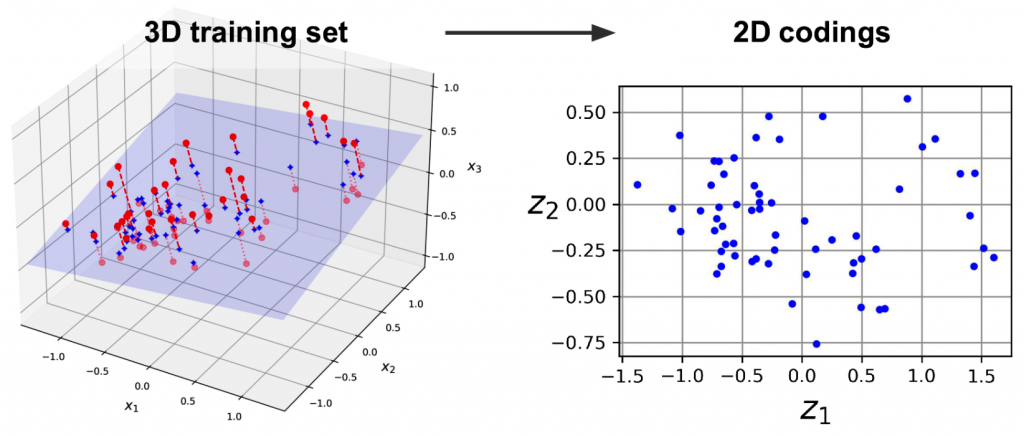
而encoder的内部表示,一般都会比输入数据维度更少,因此它必须要找到表达输入的高效方式,从而学习到输入数据的最重要的特征,抛弃掉不重要的特征。这种特性,也经常被用来做降维(比如PCA)。
encoder和decoder都使用最基本的线性模型,不使用任何的激活函数。代价函数也使用基本的均方误差(MSE)。比如3D的数据集,经过PCA之后,encoder识别到了最佳的2D投射平面,从而将3D的数据集降维到2D空间内。
encoder可以看作进行了一个自监督学习,其标签就是原始的输入。
堆叠自编码器(Stacked Autoencoders)
自编码器也可以有多个隐藏层,从而能学习到更加复杂的编码方式。但是必须注意的是,不能让encoder功能过于强大,从而能够完美的编码和解码,但是这种无法泛化到其他样本。
堆叠的自编码器,是一个相对于中心的隐藏层(codings layer)两边对称的架构。比如下图中,encoder会先
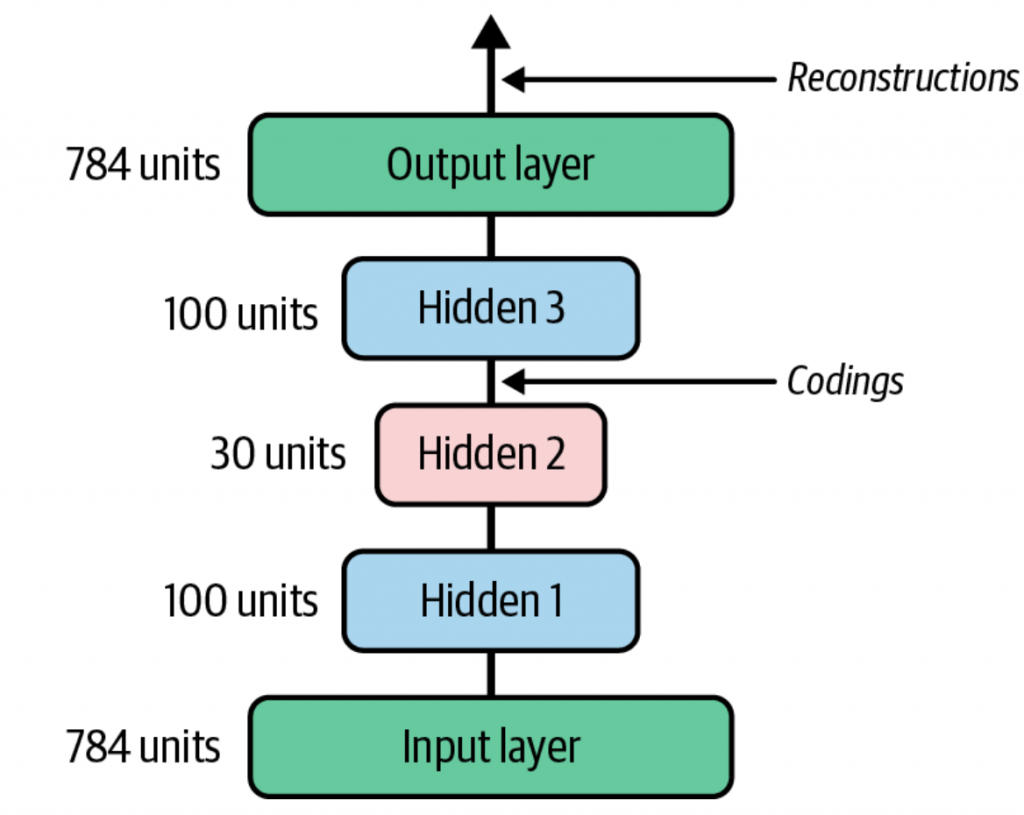
- 原始的输入是一个784维的向量,经过两次降维后,均使用ReLU激活函数,输出了30维的向量
- decoder经过两层的处理,将30维的向量恢复为784维的向量
- 在训练的时候,使用样本输入作为标签
通过自编码器进行无监督预训练
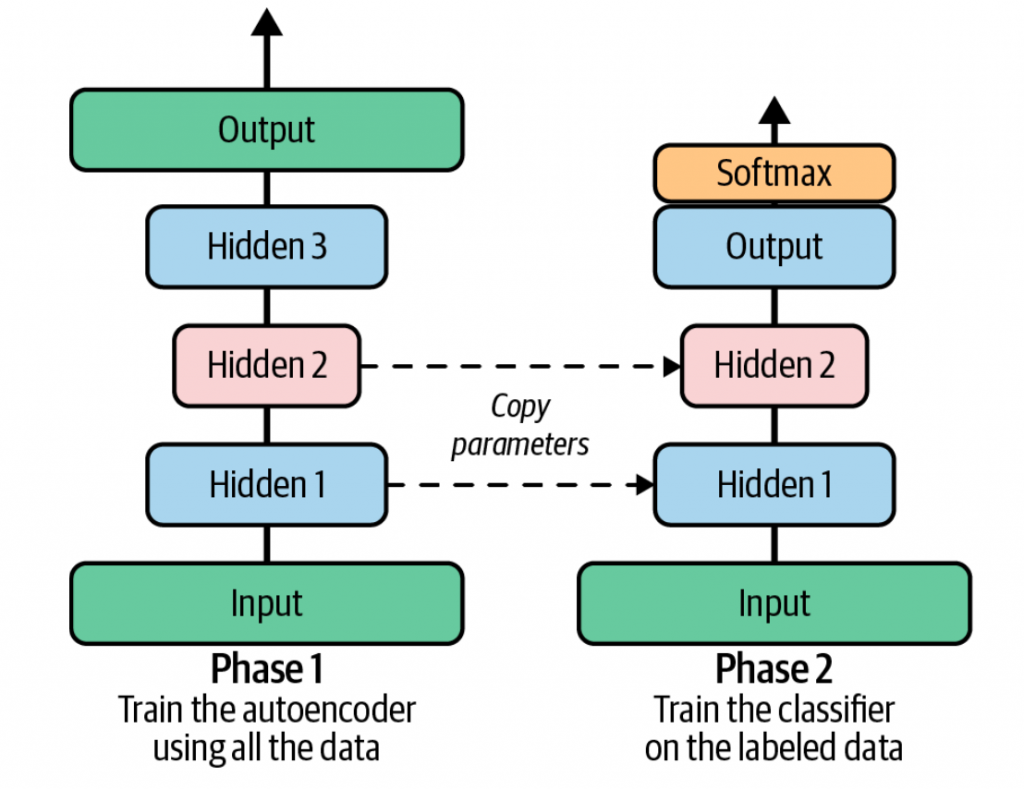
使用堆叠自编码器进行无监督预训练是一种利用大量无标签数据,通过逐层训练多个自编码器,为深度神经网络初始化一组良好权重的策略。
通过堆叠自编码器,对无标签的数据进行训练后,decoder弃之不用,encoder学习到了原始数据的重要特征,而这些特征就可以复用于有标签数据的下游训练。
权重绑定
自编码器中,encoder和decoder一般都是对称的,因此可以让对应的encoder和decoder共享同一组权重参数,而decoder的参数是encoder参数的转置。这样做的好处就是:
- 大幅减少参数量:这是最直接的好处。如果编码器和解码器层的大小对称(例如,都是784 → 128和128 → 784),绑定后参数量几乎减半。这降低了模型复杂度,有效缓解过拟合。
- 提升学习效率与稳定性:更少的参数意味着更快的训练、更少的内存占用,并且优化问题变得更简单,更容易收敛到一个较好的解。
- 产生更“纯粹”的潜在表示:绑定迫使网络在编码时必须考虑如何用同一组权重来高效地重建。这常常能引导网络学到更具代表性的潜在特征。
其他自编码器
卷积自编码器(Convolutional Autoencoders)
卷积自编码器是将卷积神经网络的架构思想应用于自编码器的产物。它专门为处理具有网格拓扑结构的数据(如图像、2D/3D医学扫描)而设计,用卷积层和池化层(或步长卷积)替代传统自编码器中的全连接层,作为encoder和decoder的主要构建模块。其组成同样是encoder和decoder
- encoder:将输入图像压缩为一个紧凑的潜在表示,由多个卷积层和池化层堆叠而成。卷积层提取局部特征(如边缘、纹理),池化层降低特征图的空间尺寸(高度、宽度),同时增加通道数。
- decoder:从潜在表示中重建出原始尺寸的图像,由多个转置卷积层堆叠而成。转置卷积逐步增加特征图的空间尺寸,并逐步减少通道数,最终输出通道数应与输入图像一致。
- 转置卷积的目标是执行上采样。也就是将一个小尺寸的特征图,“扩展”为一个大尺寸的特征图。它通过可学习的卷积核,学习“如何根据上下文来智能地填充和放大”。
相比于全连接的自编码器,卷积自编码器在处理图像时具有一些独特的优势
- 保留并利用图像的2D空间结构,所有操作都是局部的。
- 参数共享,一个卷积核在整张图上滑动使用,参数量极少,效率极高。
- 天生具有平移等变性,物体在图像中移动,其编码特征也会相应移动。
- 自然地学习层次化特征:浅层学边缘,中层学纹理/部件,深层学复杂对象。
去噪自编码器(Denoising Autoencoders)
为了能让encoder学习到更加有用的特征,可以在输入上增加高斯噪音,或者干脆随机剔除掉某些输入,就像之前的失活(dropout)那样。
它将噪声作为一种积极的约束,迫使网络深入挖掘数据背后的统计规律和本质结构,从而学习到鲁棒、抽象且有意义的特征表示。该方式同样可用于数据去噪。
稀疏自编码器(Sparse Autoencoders)
还有一种约束条件,就是稀疏性。通过在代价函数中增加额外的条件,从而限制自编码器中编码层的激活的神经元的数量。举例来说,只允许5%的神经元激活,这就会要求自编码器能够通过有限的神经元来表达输入,每个神经元能够表示输入数据的某一种特征。
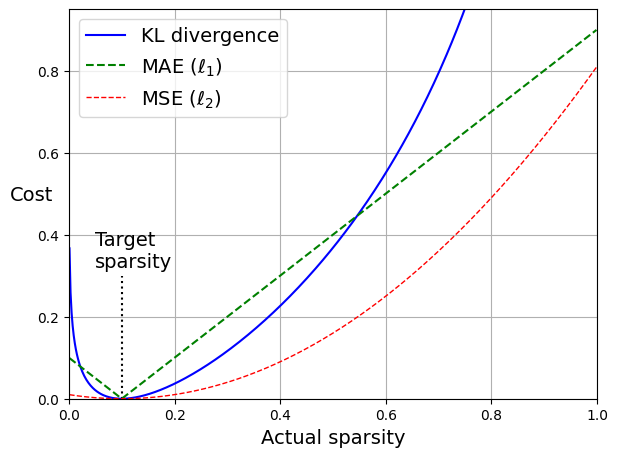
一般的做法,就是设定一个比较小的目标激活率 ρ ,当实际激活率偏离目标时施加惩罚,从而让隐藏层中每个神经元在数据集上的平均激活概率 ρ̂ 尽可能接近这个目标。
- 均方误差(MSE)惩罚
\begin{align*}
\text{MSE} &= (\hat{\rho} - \rho)^2 \\
\quad\\
\frac{\partial{\text{MSE}}}{\partial{\hat{\rho}}} &= 2(\hat{\rho} - \rho)
\end{align*}梯度变化是线性的,当 ρ̂
- KL散度(Kullback–Leibler divergence)惩罚
\begin{align*}
\text{KL}(\rho || \hat{\rho}) &= \rho * \log\frac{\rho}{\hat{\rho}} + (1-\rho) * \log\frac{1-\rho}{1-\hat{\rho}} \\
\quad\\
\frac{\partial{\text{KL}}}{\partial{\hat{\rho}}} &= -\frac{\rho}{\hat{\rho}} + \frac{1-\rho}{1-\hat{\rho}}
\end{align*}KL散度的梯度变化要比MSE大的多
变分自编码器(Variational Autoencoders)
变分自编码器是当前最为主流的自编码器,它不仅是特征提取器,更是强大的深度生成模型。它能学习数据的概率分布,生成高质量新样本。
与其他自编码器相比,变分自编码器在以下特定方面存在显著差异:
- 它们是概率自编码器,这意味着即使在训练结束后,其输出仍部分取决于随机抽样(这与去噪自编码器形成鲜明对比,后者仅在训练阶段引入随机性)。
- 最重要的是,它们是生成式自编码器,这意味着它们能够生成看似从训练集中采样而来的全新实例。
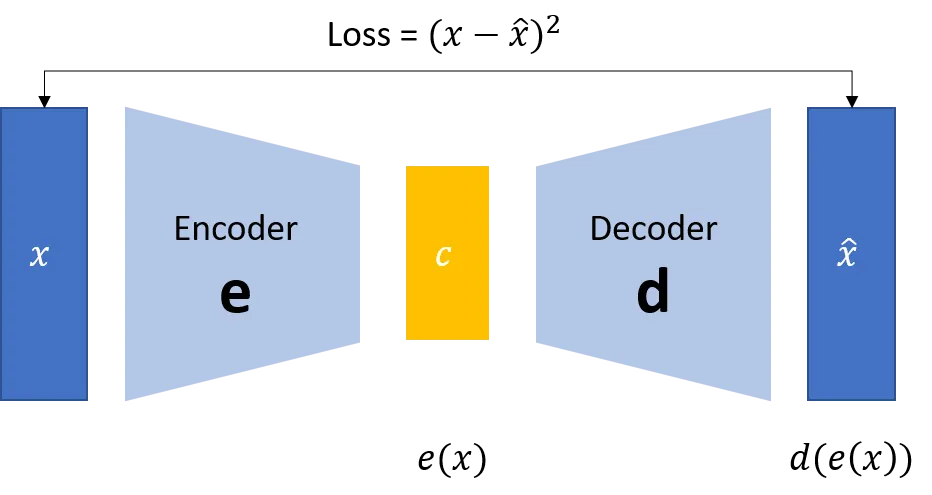
一般的自编码器,都是要尽可能发现一个高效的编码来表达输入。
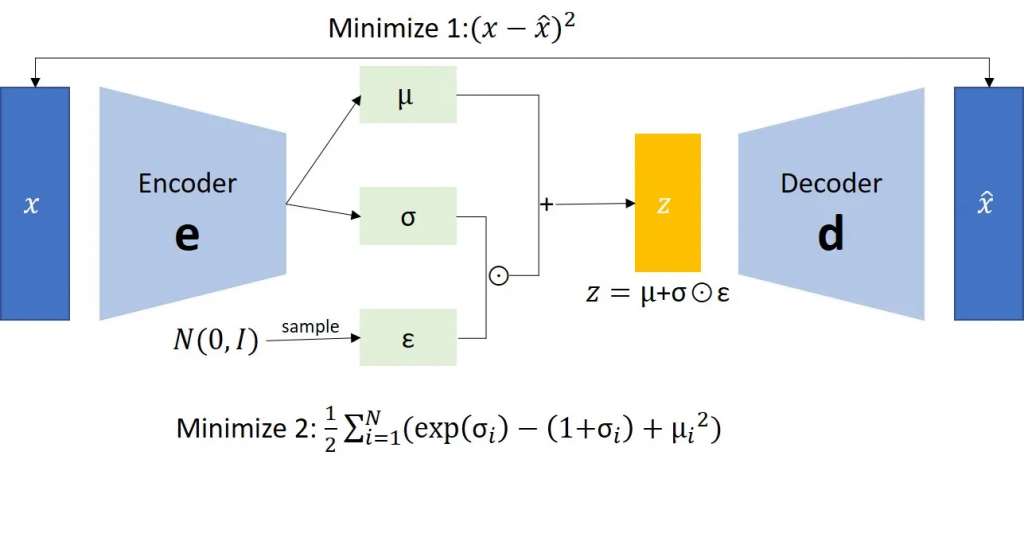
而变分自编码器,encoder输出的是一个均值编码μ,以及标准差σ。真正的编码,是从这个(μ, σ)的高斯分布中采样得出。decoder的过程与其他自编码器无异。
这里需要提及重参数化技巧(Reparameterization trick)。重参数化技巧用于将从一个概率分布中采样的随机操作,改写为一个可微分的、确定性的计算过程与一个独立的随机噪声的组合。这使得梯度可以通过该过程反向传播,从而能够用标准的梯度下降算法来优化包含随机采样步骤的模型。
z=\mu+\sigma\odot\varepsilon
目标分布与实际分布之间的误差,可以用KL散度来进行计算,其计算公式为
L=-\frac{1}{2}\sum_{i=1}^{n}[1+\log({\sigma_i}^2) - {\sigma_i}^2 - {\mu_i}^2]为了数值的稳定性,一般会让encoder输出对数方差,而不是直接输出方差
L=-\frac{1}{2}\sum_{i=1}^{n}[1+{\gamma_i}^2) - \exp(\gamma_i) - {\mu_i}^2]生成对抗网络(Generative Adversarial Networks)
GAN的构成

GAN的核心就是让两个神经网络在对抗中共同进化:
- 生成器:生成足够“以假乱真”的伪造数据
- 判别器:学习如何辨别生成的伪造数据,辨别成功则会惩罚生成器
GAN的两个神经网络,其训练目标是不相同的,因此需要特别的训练过程。每次迭代会包含两个阶段:
- 阶段一,训练判别器。生成器的伪造数据,和训练集的真实数据混在一起,用不同标签标识真假数据,从而用来训练判别器,这一阶段的反向传播,只会调整判别器的权重。
- 阶段二,训练生成器。生成器生成一批数据,都打上真实标签,用判别器的识别准确率来训练生成器。此阶段会冻结判别器的权重,仅优化生成器的权重。
这两个阶段中,生成器从来没有看到真实数据,都是靠判别器的结果来逐步学习如何生成更真实的数据。因此判别器效果越佳,生成器得到的提升也就越大。
训练GAN的难点
纳什均衡(Nash equilibrium)
纳什均衡有两种场景:
- 协调博弈
- 所有参与者的利益是一致的,比如驾驶汽车,选择同侧驾驶对所有人都是最好的结果,是一个共赢的局面。
- 其最优策略是确定的,要么都靠左,要么都靠右。
- 状态是收敛且可终止的。当所有人都靠右行驶后,博弈就结束了,系统达到一个宁静的、自我维持的稳定点。
- 零和博弈
- 参与者的利益完全对立,比如捕食者和猎物,是一种你死我活的竞争关系。
- 没有一个确定性的策略,最优策略表现为一个混合策略的概率分布。捕食者不能总是捕食,猎物也不能总是逃跑。
- 均衡不是指博弈停止,而是指博弈策略达到一种平衡。捕食者仍在追逐,猎物仍在逃跑,只是双方使用的策略比例达到了最优,任何一方单独改变这个比例都会吃亏。
模型坍塌(Model Collapse)
尽管GAN的作者说,GAN的训练最终会达到第一种均衡场景,生成器生成完美的图片,导致辨别器无法有效辨别,只能50/50地猜测。
但是现实训练中,经常会遇到模型坍塌的问题,也就是:生成器退化到一个极小的模式子集,失去了生成真实数据完整分布的能力。它不再生成多样化的样本,而是反复生成非常相似甚至完全相同的少数几种样本。
模型坍塌的原因有以下几点:
- 判别器过于强大,能够识别所有的伪造数据,从而导致生成器的损失函数梯度很小,无法获得优化的方向,从而停滞不前。
- 生成器寻求捷径,当发现某些样本更容易欺骗识别器时,就会强化学习这些样本,而忽略了其他样本。
深度卷积GAN(Deep Convolutional GANs)
DCGAN的一些设计准则
- 生成器
- 使用转置卷积层进行上采样,逐步将低维噪声向量转换为高分辨率图像。
- 去除全连接层,以全卷积结构构建网络。
- 在除输出层外的每一层后使用批归一化,加速训练并稳定学习过程。
- 激活函数使用ReLU,输出层使用Tanh将像素值约束到[-1, 1]。
- 辨别器
- 使用带步长的普通卷积层进行下采样,逐步缩减空间尺寸并增加通道数。
- 同样采用全卷积结构,最终通过一个全局平均池化或全连接层输出单一概率值。
- 每一层后使用批归一化(但第一层有时省略)。
- 激活函数使用LeakyReLU,防止梯度稀疏。
- 输出层使用Sigmoid输出真实概率。
DCGAN的优势在于:
- 空间结构感知:卷积操作天然适合图像,能保留并利用局部与空间相关性。
- 参数效率:权重共享大幅减少参数量,降低过拟合风险。
- 训练稳定性:批归一化缓解了梯度消失/爆炸问题,使深层网络训练成为可能。
- 生成质量:首次能够生成较清晰、具有一定多样性的自然图像(如人脸、室内场景)。
渐进式增长GAN(Progressive Growing of GANs)
渐进式增长GAN的核心思想,就是从低分辨率(如4×4像素)开始训练生成器和判别器,待训练稳定后,逐步向网络中添加新的层,使图像分辨率逐级翻倍(8×8, 16×16…),直至达到目标分辨率。
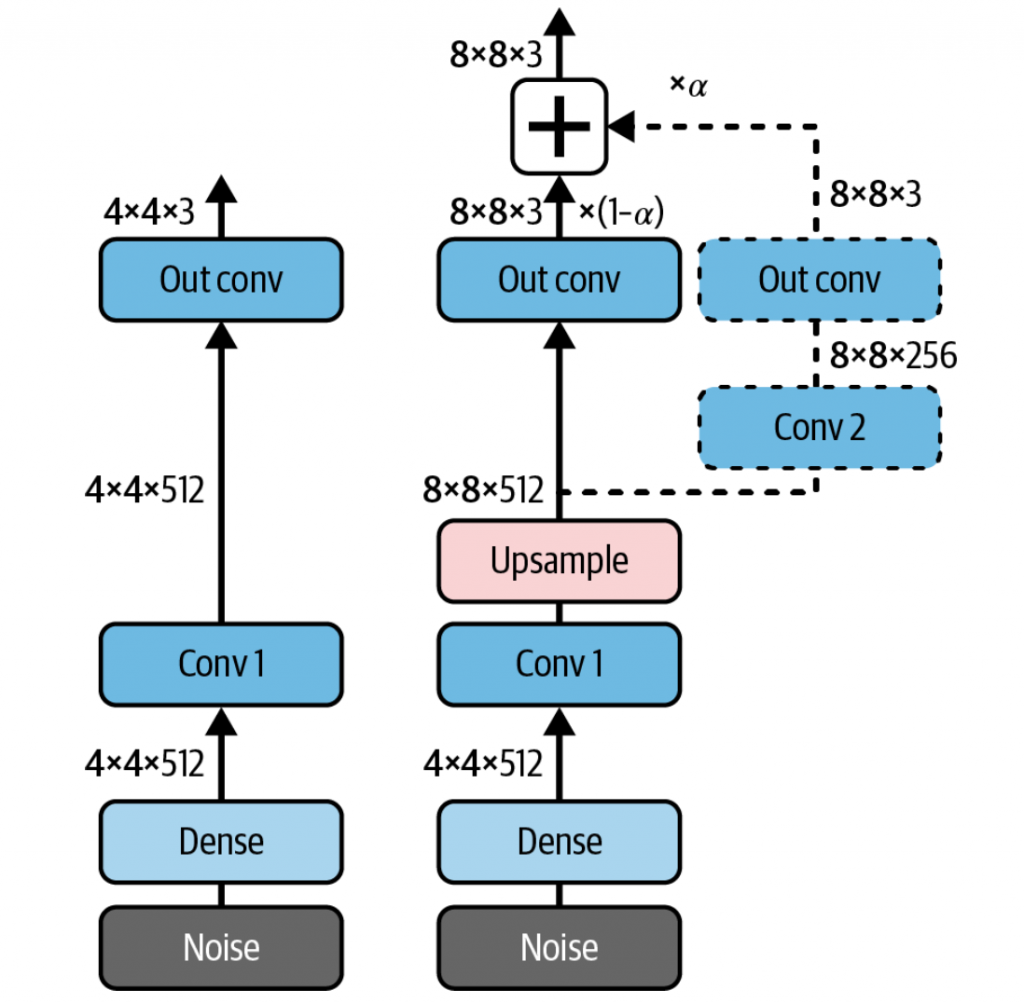
上图就是渐进式增长GAN的一个训练过程说明,其过程包含两个主要阶段,循环进行
- 稳定训练阶段。如上图的左侧,经过一段时间后,在4*4的分辨率上达到相对平衡
- 渐进增长阶段。上图的右侧部分,向生成器和判别器中添加新的更高分辨率的层,从而产出更高质量的图像。同时,这里通过权重因子
α,将新旧两路的输出进行加权融合。随着训练进行,α从0变为1,网络平滑地从依赖旧的低分辨率路径,过渡到完全依赖新的高分辨率路径。
小批量标准差层
小批量标准差层,会加在判别器的末端,它的核心目的是通过让判别器能够感知并利用当前整个小批次内样本的统计特性,来有效缓解生成器的模式崩溃问题,从而激励生成器产出更多样化的样本。
对于每一个位置点,会计算这一批次所有通道所有样本的标准差,然后再计算所有位置点标准差的平均值。如果生成的样本非常雷同,那么其标准差就会很小,从而让判别器很容易识别出模型坍塌。
风格生成对抗网络(StyleGANs)
StyleGAN 是生成对抗网络发展史上的一个里程碑,作者在生成器中采用了风格迁移(style transfer)技术,以确保生成图像在每个尺度上都与训练图像具有相同的局部结构,从而显著提升了生成图像的质量。判别器与损失函数均未作修改,仅调整了生成器。
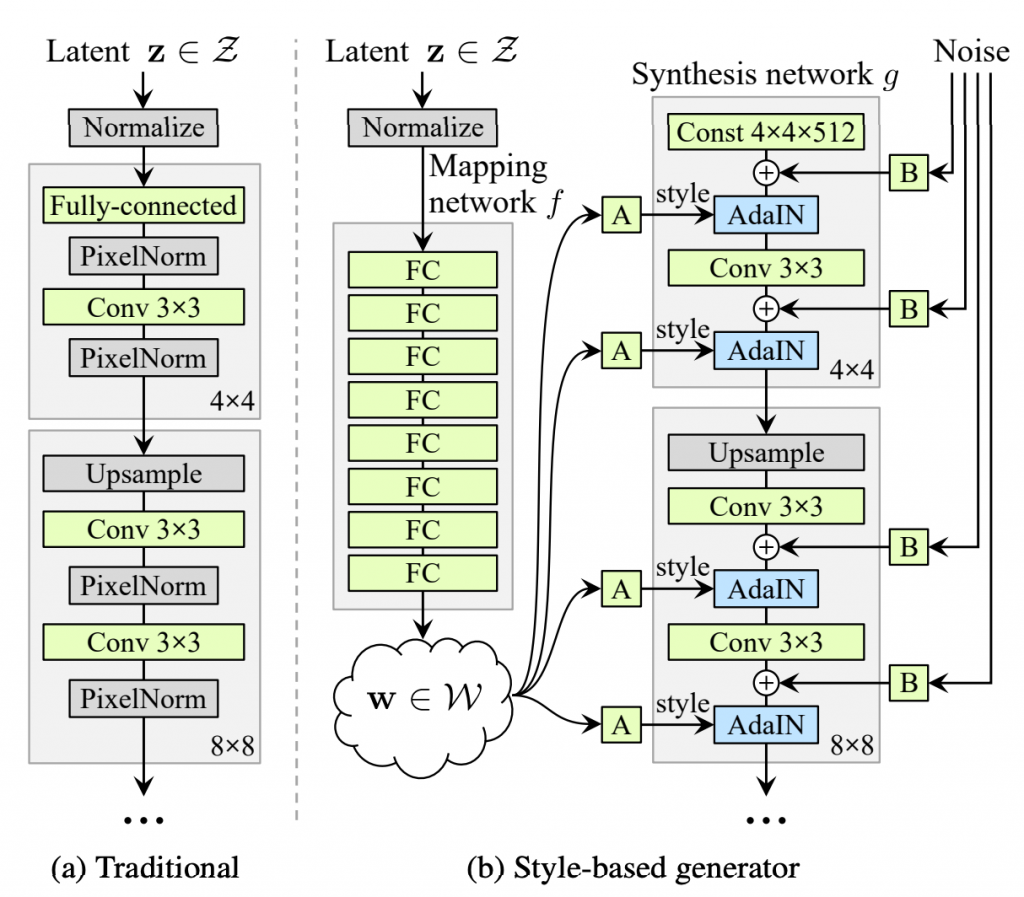
上图就是原论文中的StyleGAN的架构,主要包含两个网络:
映射网络(Mapping network)
将输入噪声向量 z ,通过一个8层的多层感知机,映射到一个中间潜在空间 W 。而向量 w 经过多个仿射变换(图中的A)后,生成了多个向量。每个向量都控制着图像的一种风格,比如头发颜色、人物肤色、大人小孩等。
合成网络(Synthesis network)
负责生成图像,本质上是一个高度专业化、由风格驱动的图像解码器。相比于传统的生成器,主要有以下几点区别:
- 常数输入:合成网络的起始输入是一个可学习的常数张量(例如,4x4x512)。这个张量在训练中被优化,作为整个生成过程的“基础画布”或“初始种子”,从而迫使所有与图像内容相关的可变信息都必须通过后续的风格注入(AdaIN)来引入。
- 随机噪声输入:为了生成逼真的随机细节(如雀斑、发丝走向、皮肤纹理),早期的GAN,这些随机性要么来自编码层,要么是生成器自己随机生成的噪声。如果是编码层的随机性,那么编码层就需要想办法存储这些信息,其实是比较浪费的。而且,在不同层使用相同的这些噪音,就会导致一些人为视觉效果,从而影响最终图片的真实性;如果是生成器自己随机生成,那么也会导致人为视觉效果,而且一部分权重就会被用来表达这些随机性,同样也会导致浪费。StyleGAN在合成网络每个卷积层之后,向特征图中添加逐像素的高斯噪声。这些噪声是单通道的,通过一个可学习的、每通道独立的缩放因子(图中的B)进行调制后,再加到特征图上。
- 混合正则化:将两个编码向量
c1和c2,通过映射网络后,生成两个style向量w1和w2。在合成的时候,故意用w1生成某些层,用w2生成剩余的层,从而强制模型学习到更加解耦、更加局部化的风格表示。