自然语言处理
Encoder-Decoder
神经机器翻译模型(NMT)
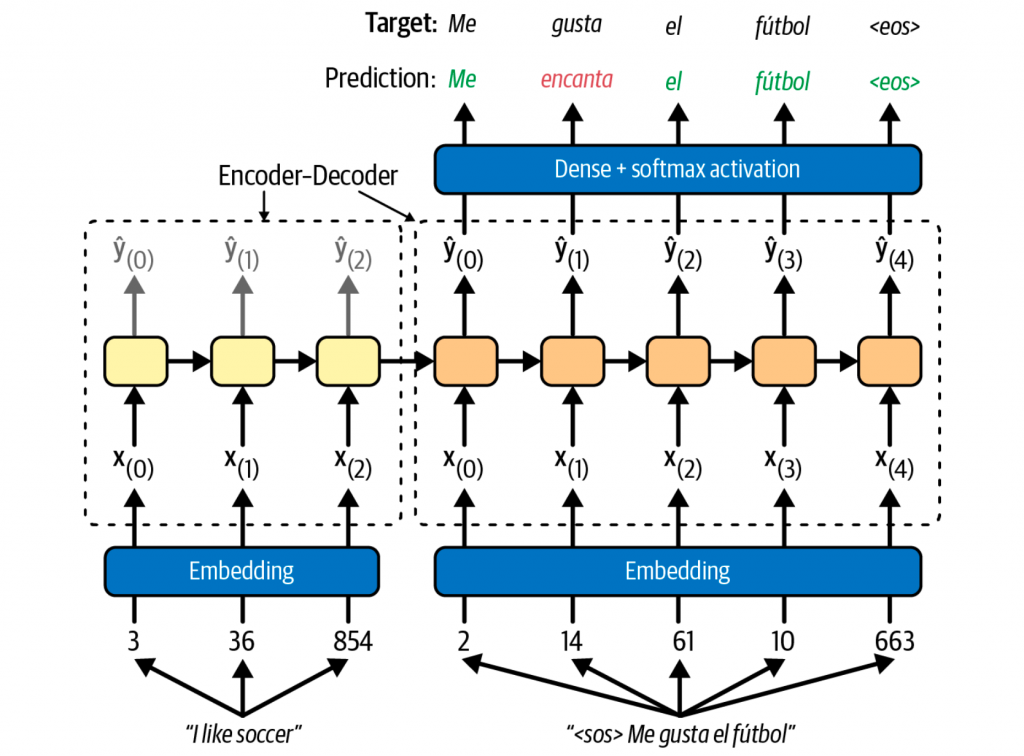
一个英语翻译为西班牙语的翻译模型,主要包含encoder和decoder两部分。英语作为encoder的输入,而decoder会输出西班牙语。
而在训练的时候,西班牙语也会作为decoder的输入,而且不使用它上一时刻的预测输出作为当前时刻的输入,而是强制使用训练数据集中真实的、正确的上一时刻目标值作为输入。这种方式称为teacher forcing,从而避免模型预测越来越错。
在推理的时候,decoder是没有目标语言作为输入的,这时候只有将上一步的输出作为输入。
双向RNN(Bidirectional RNNs)
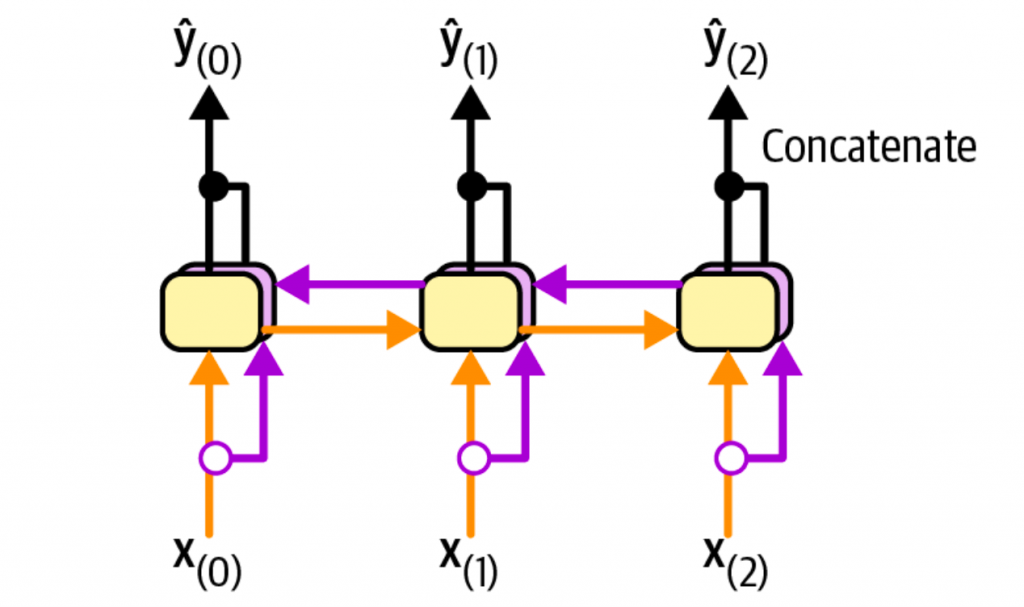
在翻译过程中,由于只能看到之前的输入,看不到未来的输入。在预测场景,或者seq-2-seq模型的decoder阶段,仅看到过去的输入是合理的。但是对于encoder阶段,还是最好能看到未来的输入。比如在翻译场景,right翻译为正确,还是翻译为权利,往往要根据后面的语义来判断。
一种办法,就是使用两个方向上的输入,一个从左到右,一个从右到左。如下图所示
Beam Search
如果每一步都只选择当前概率最高的词,快但容易陷入局部最优,错过全局更好的序列。在每一步,它保留概率最高的 k 个(k 称为束宽)候选序列进行扩展,而不是仅仅一个。这个简单而强大的策略,让它能更大概率地找到全局更优的序列。
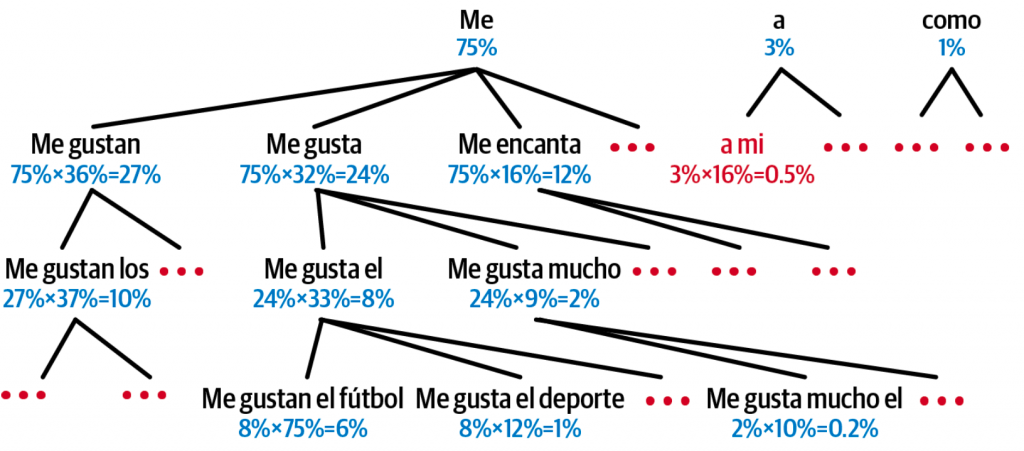
对于较短的语句,可以通过双向RNN和Beam Search两种办法来进行优化,但是对于长句仍然表现不佳,主要还有因为RNN的短期记忆。
注意力机制(Attension Mechanisms)
注意力机制,允许神经网络在处理信息时,能够动态地、有选择地聚焦于输入数据中最相关的部分,而不同等重要地处理所有信息。这模仿了人类的认知注意力——例如,在阅读时,你会更关注当前句子的关键词,而非均匀对待每一个字。
如下图所示,左边的encoder-decoder,之前的encoder只会将最后一步的状态发送给decoder,而现在会将所有的输出都发送给decoder。但是decoder无法处理所有的输出,因此需要将这些输出进行聚合。每一步,都会对所有输出进行加权求和,从而决定这一步的注意力应该在哪个词上。
下图中,α(t,i)代表着t时刻第i个encoder的输出。由于α(3,2)要比其他两个权重要高,因此decoder会更关注soccer这个词。
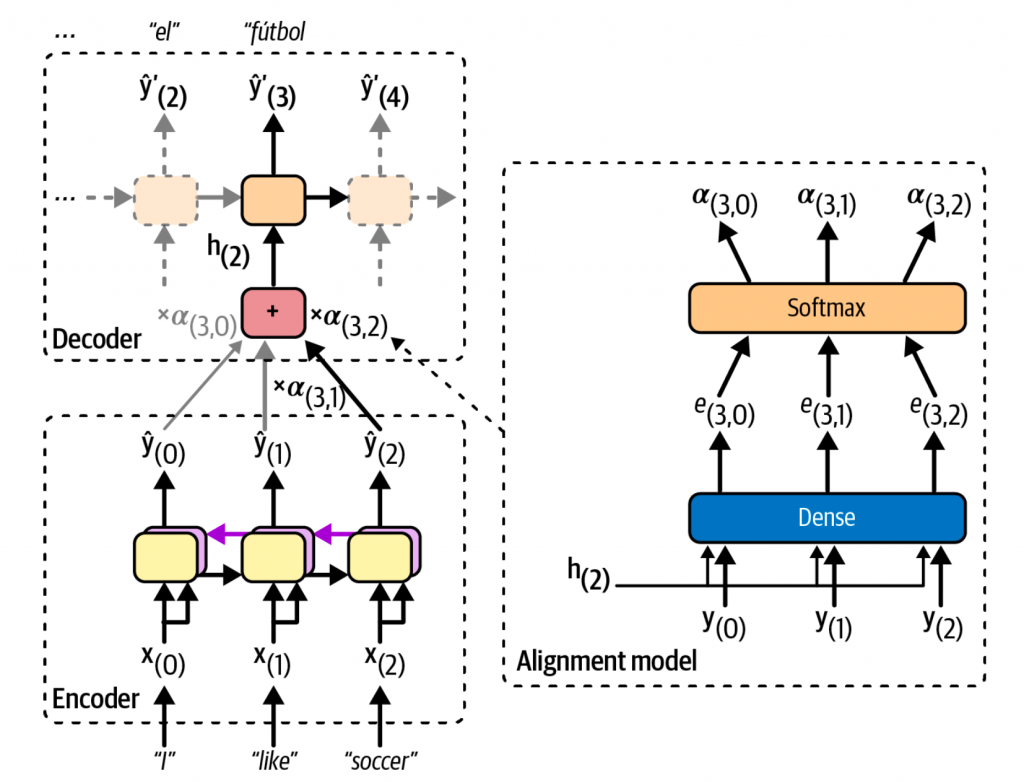
那么权重是怎么计算出来的呢? 这里就要提到对齐模型(alignment model)了。
Bahdanau注意力
上图右侧就是对齐模型的一个说明,它是一个由单个神经元构成的全连接层,它处理编码器的每一个输出,并结合解码器前一时刻的隐藏状态(例如 h(2))。该层为每一个编码器输出(例如 e(3,2))计算一个分数:这个分数衡量了每个编码器输出与解码器前一时刻隐藏状态的对齐程度。
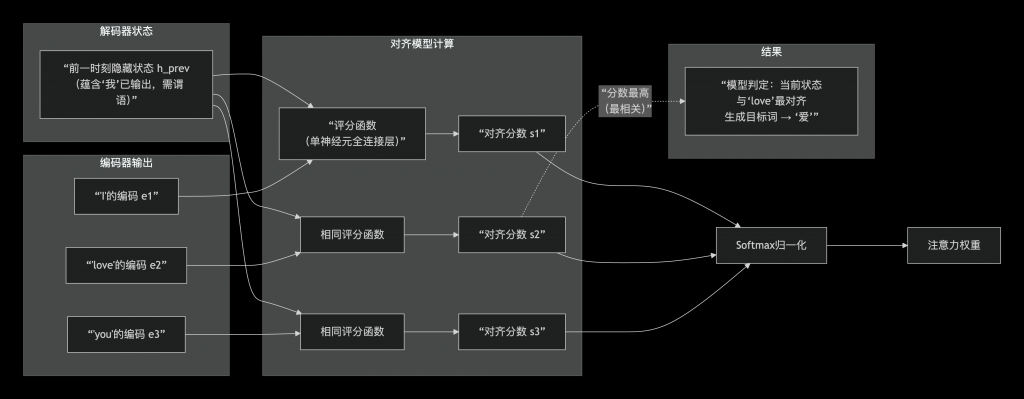
上图就是对齐模型的工作原理说明,已经输出了主语“我”,下一步大概率需要一个谓语,因此love的对齐分数最高,因为这个词与前一时刻的隐藏状态更加匹配,更加“对齐”。
\begin{align*}
\bold{\widetilde{h}}_{(t)}&=\sum_{i} \alpha_{(t,i)}\bold{y}_{(i)} \\
\alpha_{(t,i)} &= \frac{\exp{(e_{(t,i)})}}{\sum_{i'}\exp{(e_{(t,i')}})} \\
\quad\\
e_{(t,i)} &= \bold{v}^{\text{T}} \tanh{(\bold{W}[\bold{h}_{(t-1)};\bold{y}_{(i)}])}
\end{align*}Luong注意力
Luong Attention 针对 Bahdanau Attention做了相应的改进,主要体现在这两点上
计算路径
Bahdanau的计算路径,是在解码的每一步,使用解码器上一时刻的隐藏状态 h(t-1) 作为查询,去计算注意力权重,生成上下文向量 c(t)。然后,将 c(t)与当前步的输入词嵌入拼接,一起送入RNN单元,才计算出当前时刻的隐藏状态 h(t) 。
而Luong的改进,就是先让解码器RNN像往常一样,基于上一状态和输入,独立计算出当前时刻的隐藏状态 h(t)h(t)c(t) 。最后,将 h(t)c(t) 拼接,通过一个前馈层产生最终的输出。
Luong的方式更简洁、更模块化,注意力层像是一个可以轻松加在解码器顶部的插件,计算路径更短。
对齐函数
Luong对比了三种函数
- 点积:
h(t)Ty(i),计算高效,无需额外参数 - 通用:
h(t)TWy(i),引入权重矩阵W,更加灵活 - 加性:与Bahdanau的类似,只是
h(t-1)换成了h(t)
点积注意力在大多数情况下表现与加性注意力相当甚至更好,且计算成本显著更低。这直接为后来Transformer采用缩放点积注意力提供了重要依据。
Attension Is All You Need
Transformer架构,完全摈弃了RNN或者CNN,仅使用注意力机制(另加嵌入层、全连接层、归一化层及其他零散组件),就显著提升了神经机器翻译的水平。
Transformer架构
在Transformer架构中,encoder的职责就是逐步转换(transform,transfomer的由来)输入,捕捉每个词在上下文中的含义。比如“i like soccer”中的like,在英文中有很多种含义。而经过encoder处理后,该词的向量表示,就能准确捕捉这句话中like的含义,以及其他重要信息(比如这是一个动词)。
而decoder的职责,就是一个“猜词游戏”。它的transform,体现在将每个词的向量,转换为翻译序列中的下一个词的表示。解码器不是一次性吐出整个翻译好的句子,而是一个词一个词地“猜”出来的。在猜每一个新词时,它都会利用已经生成的“部分翻译”作为线索。
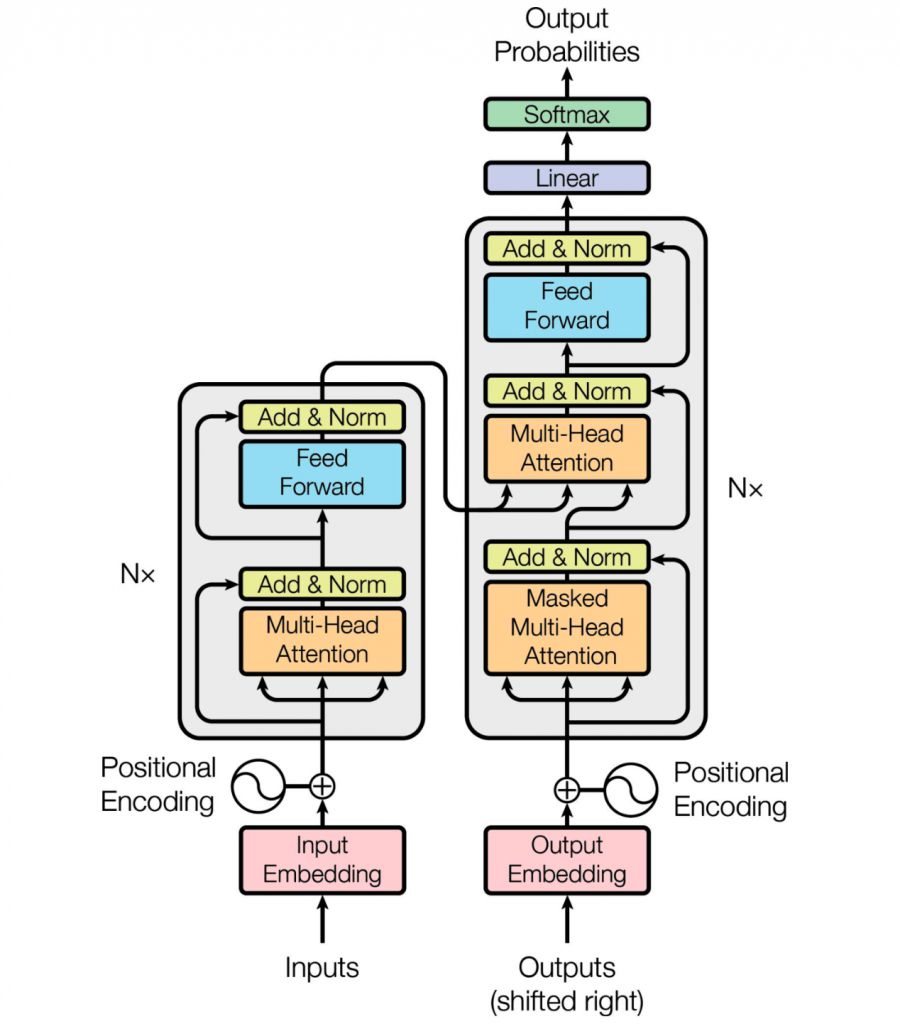
上图就是tranformer的原始架构。
- 注意力堆叠了N层,原始论文中N为6
- encoder的多头注意力,在处理每个词的时候,会“注意”句子中的其他词。每个词向量,都会变得更加准确和丰富。
- decoder的第一层,掩码多头注意力层,做的事情是类似的,只不过decoder无法看到当前词的后续,只能看到前序已经产出的结果。这一层都来源于自身的输入,不需要encoder的输出,也称为自注意力层(self-attention layer)。
- decoder的上一层多头注意力层,需要关注encoder的输出,称为交叉注意力层(cross-attention)。这一层,需要查看encoder的全部输出信息,以找到与当前decode最相关的部分。
- 位置编码(positional encoding),用来表达词在句子中的位置信息。
位置编码
位置编码最简单的方案,就是给句子中的每个位置分配一个唯一的整数或者一个可学习的位置向量。但是这种方式有比较大的问题,就是无法处理超过训练长度的句子,而且数值不稳定,索引会无限增大。
而Transformer论文中,使用了正弦余弦函数,来生成确定性的位置关系。对于一个位置为 p 的 token,其位置编码是一个维度为 d 的向量。该向量的第 i 个元素(其中 i = 0, 1, ..., d-1)的计算公式如下:
P_{p,i}= \begin{cases}
\sin(p/10000^{i/d}) & \text{ if }i为偶数 \\
\cos(p/10000^{(i-1)/d}) & \text{ if }i为奇数 \\
\end{cases}- d 决定了位置编码向量的“丰富度”或“容量”。较大的
d可以编码更精细、更复杂的位置模式。在 Transformer 的原始论文中,d 通常为 512(基础模型)或 1024(大模型) - i 决定了该维度所使用的正弦波的频率。当 i 较小时,频率较高(波长较短),对应位置的快速变化。当 i 较大时,频率非常低(波长很长),对应位置的缓慢变化。
从下图的下半部分也可以看出这个规律,当 i 较大时,波长很长,i 越小,频率越高。
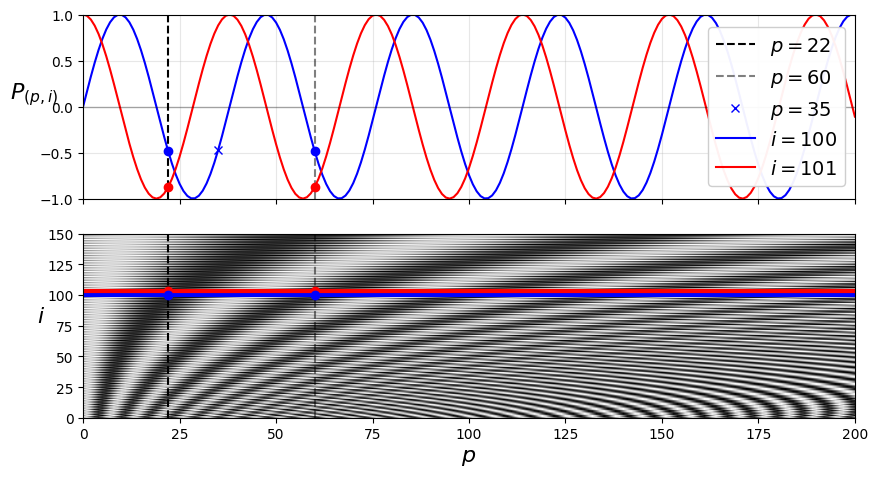
至于为什么要根据维度的奇偶,来交替使用正弦和余弦,是因为:
- 通过交替使用正弦和余弦函数,确保了每个位置的编码都是唯一的。
- 模型能够轻松地学习到位置之间的相对关系,上图中蓝色点与红色点的编码值相同。
缩放点积注意力(Scaled dot-product attention)
多头注意力的基础,就是缩放点积注意力(Scaled dot-product attention),其公式为
\text{Attention}(\bold{Q, K, V}) = \text{softmax}(\frac{\bold{QK^T}}{\sqrt{d_{keys}}})\bold{V}- Q 为查询矩阵,每一行都是一个query,一共dkeys个列。
- K 为键矩阵,每一行都是一个key,一共dkeys个列。
- V 为值矩阵,每一行都是一个value,一共dkeys个列。
至于为什么要进行缩放,是因为假设查询 q 和键 k 都是均值为0方差为1的独立随机变量。那么点积 Q·K 的均值为0,方差为 dk。当 dk 很大时,点积结果的方差也会变得非常大。
Softmax 函数对非常大的输入值非常敏感:它会将绝大部分概率质量分配给最大值,导致其他位置的梯度变得极小(接近0)。将点积结果除以 ,相当于将其标准差重新缩放回约1。这使得 Softmax 函数的输入位于一个梯度更明显的区域,从而稳定了梯度,加速了训练。
多头注意力(multi-head attention)
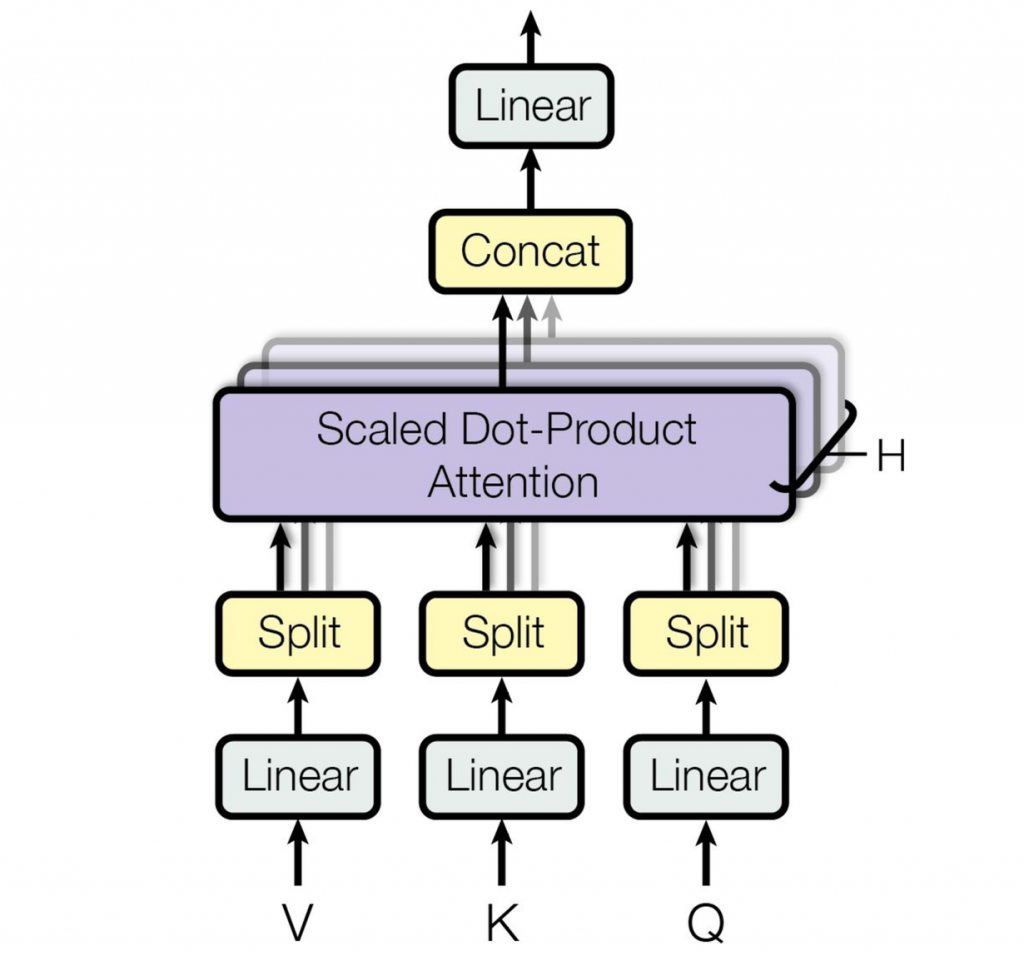
上图就是多头注意力的架构图,可以看出就是多个点积注意力组装在一起,每个注意力都处理Q、K、V的一个线性变换。所有的输出简单地拼接在一起,并通过最后的一个线性变换。
这里为什么需要使用多个注意力?模型通过将Q、K、V通过不同的线性变换矩阵,映射到不同的子空间,从而捕捉到这个词不同方面的特征。比如针对like这个词,某个头捕捉到这个词是个动词,另一个头捕捉到这个词是一般现在式。