传递事件流
在批处理中,作业的输入是文件,写入一次后可以被后续作业多次读取。而流处理中,输入则是一个事件(小的不可变对象,包含某一时间点的所有细节)。事件由生产者生成一次,可以被多个消费者消费。相关的事件聚合为一个topic或者stream。
原则上,消费者可以通过轮询来获取生产者最新的消息。但是,这种机制代价太大,最好是新事件出现的时候,自动通知消费者。因此,需要有专门的系统来处理事件通知。
消息系统
消息系统负责将生产者发送的消息,推送给订阅消息的消费者。实现方式有多种:
直接从生产者传递给消费者
即直接在两者之间建立网络通信,不通过中间节点,比如:
- UDP multicast广泛应用于金融行业,这些场景需要低的延迟,虽然UDP本身不可靠,但是通过应用层协议可以恢复丢失的数据。
- 无代理的消息中间件,比如ZeroMQ,是通过TCP或IP多播来实现消息传递。
- 生产者可以通过回调,将消息推送给消费者。参见webhooks
Webhooks are “user-defined HTTP callbacks”. They are usually triggered by some event, such as pushing code to a repository or a comment being posted to a blog. When that event occurs, the source site makes an HTTP request to the URL configured for the webhook.
https://en.wikipedia.org/wiki/Webhook
这种方式需要应用代码感知丢失数据的可能性,而且容错的方式十分有限,需要依赖生产者和消费者都必须在线。
消息代理
一种替代的方式就是通过消息代理(message broker)来发送消息。消息代理可以看作是针对消息流优化的数据库。它作为服务端运行,生产者和消费者作为客户端,生产者将消息写入broker,消费者再通过broker读取消息。
数据在broker中的持久化策略,有的是直接缓存在内存中,有些是直接写入磁盘中。如果消费消息的速度太慢,通常会放入队列(而不是丢失消息或者反压)。这样的话,消息其实是异步消费的,生产者只需要等待broker返回成功,不需要等待消费成功。
消息代理与数据库的差异
- 数据库会一直保留数据直到显式被删除,但是消息代理保留周期不会太长,只作为中转站。
- 用户选择部分数据的工作机制不同,数据库中是通过各种索引去检索,而消息代理是通过订阅主题来过滤数据。
- 查询数据库时经常是基于某个时间点的快照,如果有数据变更,需要再次查询才能获取最新结果。而消息代理虽然不支持任意方式的查询,但是数据变化会通知消费者。
这些关于消息代理的观点,被应用在JMS和AMQP等标准中,具体实现有RabbitMQ、ActiveMQ、Google Pub/Sub等。
多个消费者
当多个消费者需要从同一个主题中读取消息时,有两种消息传递方式:
- 负载均衡(load balance) —— 消息会发给某一个消费者,多个消费者之间可以并发消费
- 扇出(fan-out) —— 每条消息会发给所有消费者
确认和重试
为了避免消费者崩溃而造成消息未处理,通过确认(acknowledgments),消费成功后才会将消息从broker中删除掉。
如果未收到确认,broker则认为消息未处理,从而将消息发给另一个消费者。当使用负载均衡的时候,很有可能消费的顺序和发送的顺序匹配不上。为了避免乱序的问题,可以不使用负载均衡的方式,让每个消费者处理单独的队列。
分区日志
批处理的一个关键特性就是,输入是只读的,可以任意运行作业而不用担心损害输入。而JMS/AMQP风格的消息则不是这样,收到消息后会从队列中删除消息,从而无法重新运行并得到相同的结果。
如果将新的消费者加入系统,那么只能收到注册之后的消息,之前已经被处理的消息已经被删除掉了。而数据库的数据一直都在,新的消费者也可以随时读取。
如果将两者的想法进行结合,又有持久存储的特性,又有消息传递的低延迟特性,这就是基于日志消息代理(log-based message brokers)背后的想法。
使用日志进行消息存储
日志只是磁盘上append-only的记录序列,生产者在日志结尾增加记录,消费者顺次读取日志来消费消息。如果已经读取到了末尾,则等待新的消息到来,类似于tail -f。
为了提高吞吐量,可以对日志进行分区,各个分区之间相互独立。不同的分区可以托管在不同的机器上。一个主题就可以定义为一组携带相同类型信息的日志。
在每个分区内,broker为每条日志都分配了一个单调递增的序号,也被称为偏移量(offset)。因为分区是append-only的,所以分区内的消息是完全有序的。
Apache Kafka和Twitter的DistributedLog都是基于日志的消息代理。
日志与传统消息的对比
日志天然就支持fan-out的消费方式,因为消息处理后不会删除消息,所有消费者只是设置了对应的偏移量,都可以读取相同的消息。
而要支持负载均衡的消费模式,则可以将分区分配给多个消费者,而不是单条消息。消费者在消费单个分区的时候,通常都是简单的单线程顺序处理。但是这种方式有一些缺点:
- 并发工作的节点数,最多只能是分区数,因为每个分区都仅能被一个消费者处理。
- 如果消息处理过于缓慢,会阻塞后续消息的处理。
因此,如果消息处理比较耗时,顺序又不太重要的时候,可以采用传统的日志处理方式。另一方面,在消息吞吐量高,顺序很重要的场景下,可以使用基于日志的方式。
磁盘空间使用
为了避免日志耗尽磁盘空间,一般都会定期回收旧的日志。日志实现了一个大小有限的缓冲区,缓冲区填满会删除旧消息,被称为环形缓冲区(circular buffer / ring buffer)。
当消费者的消费速度落后于生产者的时候,可以缓冲/丢弃/反压,基于日志的方式就是缓冲的一种形式。但是如果消费者远远落后,那就会读取不到被删除的消息,所以需要配置一定的报警。
重播旧消息
基于日志的消息消费不会产生任何的副作用,仅仅是偏移量的前推。但是消费者可以控制这个偏移量,因此可以重复处理相同的消息,适合进行各种试验性的作业。
流与数据库
变更数据捕获
通过变更数据捕获(chang data capture,CDC),可以捕获数据库中的数据变更,并不断将变更应用到其他系统。如果按照顺序去消费,那么预期的结果和原始数据库的数据将会保持一致,如下图所示:
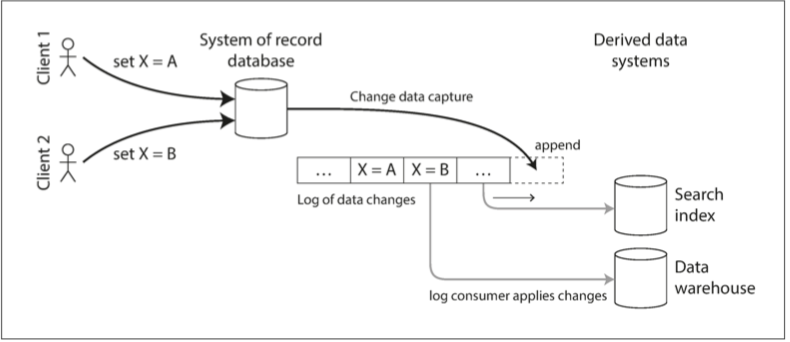
CDC的实现
可以通过数据库的触发器来实现CDC,通过注册所有的变更触发器,并将相应的变更信息写入日志表。但是触发器会有明显的性能开销,相比而言,解析复制日志更加稳妥,比如Linkedin的Databus,Facebook的Wormhole,Oracle的GoldenGate等。但是发生schema变更的时候,也会很有挑战。
和消息代理一样,变更数据捕获也是异步的,所以会有复制延迟的问题。
初始快照
理论上来说,拥有所有的数据库变更的日志,那么可以从零构建一个完整的数据库。但是这样会占用太多的磁盘空间,而且重放也太耗费时间。所以会从一个一致性快照开始,处理这个时刻之后的变更记录。
日志压缩
日志可以进行压缩,相同的键只存储最新的一条记录即可。这样日志占用的磁盘空间,就仅取决于数据库的当前内容,而不取决于写入的次数。这样的话,重建一个索引,就可以从0偏移量处依次读取消息,就能获取到所有键的最新值,这样就不用从源库获取一个一致性快照了。
事件溯源
事件溯源(Event sourcing)和CDC同样都是应用状态变更,存储成变更事件日志,但是存在不同:
- CDC场景下,应用可以任意修改和删除记录,变更日志是从数据库底层提取的。
- 在事件溯源场景下,事件日志是不可改变的,事件存储是仅追加,不建议进行更新和删除。事件是反映应用层发生的事情,而不是底层的状态变更。
Event sourcing is an architectural pattern that is gaining popularity as a method for building modern systems. Unlike traditional databases which only store and update the current state of data, event-sourced systems store all changes as an immutable series of events in the order that they occurred and current state is derived from that event log.
The stream comprises a log of all events that have occurred, and by replaying them the current state can be derived. That can give the same end-result as in a traditional database, and much more; you can perform additional tasks such as time travelling through the system and root cause analysis. And being immutable it provides one of the strongest methods for audit log available.
https://eventstore.com/
从事件日志中推导出当前状态
相比于事件日志本身,用户更期望看到当前的状态。因此需要从事件日志转换成当前状态,这个转换过程需要是确定性的,以便能再次运行。但是这里的日志压缩方式会有所不同:
- CDC的日志,只需要记录当前版本,因此日志压缩可以丢失掉同一个主键的旧事件。
- 而事件溯源,日志记录的是用户操作的意图,而不是因为操作而发生的状态变更。所以这种情况下,后续事件无法覆盖前面的事件。
命令与事件
事件溯源需要区分命令(Command)和事件(Event),用户的请求最一开始是Command,这个请求需要进行前置的一些校验,并不保证成功。如果校验通过且命令被接受,则变成了持久化且不可变的事件。
事件生成后,就变成了事实(Fact)。事件流的消费者不允许拒绝事件,因为事件是已经发生过的,且已经持久化到了日志中。
状态、流和不可变性
状态是会变化的,而且状态的这个变化是期间内所有事件修改的结果。因此,状态的可变性,和不可变事件的日志追加,它们之间并不矛盾。而上文说的日志压缩,则是状态与日志之间的桥梁。
Well, if EVERYTHING in the history of the database is represented in the log, what is the actual database itself? Well, it is a rollup of a view of the changes represented in the log. The database is a cache of a subset of the log (the subset that represents the latest updates to all the records by the transactions that happened to commit).
https://docs.microsoft.com/zh-cn/archive/blogs/pathelland/accountants-dont-use-erasers
不可变事件,一方面有利于后续的审计,另一方面也比当前状态包含更多的信息。比如,顾客先加入购物车,后续又移除,事件日志将会记录这两个操作,从而更准确分析用户行为。
从同一事件日志派生出多个视图
从同一个事件日志中可以根据查询场景,衍生出多种不同的查询视图。如果想增加一种新功能,以新的方式来表现数据,那么可以从事件日志中构建出优化后的新视图,而且不用担心影响之前的系统。
因此,如果不用关注查询和访问的话,那么数据的存储是非常简单的。schema的设计、索引及存储引擎的选择等,都是为了满足特定场景的查询需求。可以将数据的写入和数据的查询进行分离,并允许有多种不同的查询视图,这种思想也被称为CQRS(command query responsibility segregation)。
使用聚合、事件溯源和 CQRS 开发事务型微服务
- 事件溯源的优点
- 准确的审计日志
- 每个聚合的完整历史
- 持久化的是事件而不是聚合,结构相对而言更加简单
- 事件溯源的缺点
- 事件的schema会随事件发生改变,所以生成快照的时候需要面对多种schema
- 针对事件存储的查询会很有挑战,因此需要通过CQRS来解决查询的问题
- 使用CQRS来实现查询
- CQRS将应用分成了两部分,第一部分是命令端的,用于命令处理(例如,HTTP POST、PUT 和DELETE),实现创建、更新和删除聚合。应用的第二部分是查询端的,通过查询聚合的一个或更多的物化视图实现查询处理(例如HTTP GET)。通过订阅命令端服务的事件,查询端将保持视图与聚合的同步
- 每个查询端视图可使用任何类型的数据库实现,只要该数据库对要求的查询提供良好的支持
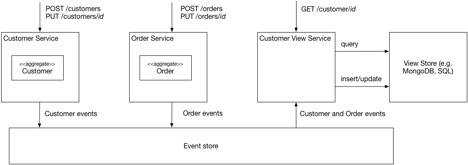
并发控制
事件溯源和CDC最大的缺点,就是消费者的消费通常是异步的,所以日志写入后,有可能在查询视图中还没出现最新的记录。
一种解决方案是将事件写入日志的同时,同步更新查询视图,需要包含在一个事务中。另一方面,事件日志也能简化并发控制。因为许多对于多对象事务的需求,是需要用户在不同的位置修改数据,有了事件溯源后,用户只需要在一个地方修改(就是添加事件日志),很容易原子化。
流处理
流处理的应用
CEP
CEP(Complex Event Processing)允许用户在数据流中搜索某些特定的事件。查询和数据的关系,与数据库相比正好颠倒。数据库中会持久存储数据,而查询是临时的(因为查询的时候,数据库检索与之匹配的数据,查询完成后丢弃查询)。而CEP引擎则正好相反,查询是长期存储的,而数据流中的事件不断流入,并检索与之匹配的特定模式的事件。
流分析
对流进行分析是最广泛的应用场景。统计值都是在固定的时间窗口(window)内进行计算的。流计算有可能会使用概率算法,比如Bloom filter、HyperLogLog的估计算法。
维护物化视图
事件溯源的场景下,会通过事件日志衍生出一个物化视图,从而提升查询效率。物化视图不能仅考虑某个时间窗口,还需要任意时间段内的所有事件。
搜索流
CEP是搜索由多个事件构成的模式,同时也存在基于复杂标准来搜索某个事件的需求。搜索方式和CEP差不多,都是保存下查询,然后对流中的每个事件进行检索。当查询越来越多的时候,检索就会变得很慢,可以通过建立索引来缩小检索范围。
时间窗口
窗口类型
- 滚动窗口(Tumbling Window) —— 有固定的宽度,每个事件只能属于一个窗口。比如1分钟的滚动窗口,则14:00 ~ 14:59、15:00 ~ 15:59就是相邻的滚动窗口。
- 跳动窗口(Hopping Window) —— 跳动窗口也是有固定的长度,但是允许相邻的窗口合并,从而实现平滑。跳动窗口也会有一定的步长,比如1分钟步长的5分钟窗口,就是14:00 ~ 18:59,15:00 ~ 19:59。
- 滑动窗口(Sliding Window) —— 滑动窗口包含了间距在特定时长的所有事件,边界不固定。
- 会话窗口(Session Window) —— 会话切分同网站的访问,比如30分钟内无访问就视为新的session。
流式关联
流流关联(窗口连接)
如果将搜索事件和点击事件进行关联,用户搜索出结果后,多长时间去点击这个结果是不确定的,所以一般都是要选择一个合适的窗口,比如1个小时内的。
流表关联(流扩展)
比如用户浏览事件中,需要关联用户维表。用户维表中的信息,就是作为扩展信息填充到事件中。每次处理一条事件的时候,就需要查询一次维表,这样性能不会很好。如果可能的话,可以将维表全量加载到内存中,类似于MapJoin。
由于流任务是一个长时间运行的任务,数据库的内容需要保持最新,可以通过CDC来实现更新。
表表关联(维护物化视图)
通过视图来替代表表之间的join
关联的时间依赖性
由于事件没有顺序保证,那么关联的结果也会变得不明确,会导致相同的作业未必产生相同的结果。在数据仓库中,可以通过缓慢变化维(slow changing dimension)来记录不同版本的详情,但是会导致日志无法压缩。
容错
在批处理任务中,如果任务出错只需要再次运行即可,可以保证任务的输出都是相同的。看起来就像是每条记录仅被处理了一次,这个原则称为恰好一次语义(exactly-once semantics)。流处理的处理要麻烦些。
microbatching与checkpoint
一个方案就是将流分拆为一个个小块,用批处理的方式去处理,这种方式被称为microbatching,Spark streaming就是用这种方式。批次的大小被设置为1秒,也是对性能妥协的结果。
Apache Flink则提供不一样的方式,定期生成状态的checkpoint并写入存储。如果作业崩溃,从最近的一个checkpoint重启即可。checkpoint由消息流中的barrier触发,类似于批次之间的边界。
在流处理框架范围内,两种方式都提供了与批处理一致的恰好一次语义。但是,下游的额外处理,比如发送邮件等等,这是框架无法处理的,重启会导致发送多次的副作用。
原子提交
通过事务来保证算子状态变更、数据库写入等操作,要么全部成功,要么全部回滚。
幂等性
幂等性保证多次执行和单次执行的效果一致。即使有些操作不是幂等,通过某种处理也可以达成幂等。比如kafka的消息,每条消息都带有单调递增的偏移量,将值写入数据库的时候可以带上这个偏移量,这样就可以判断一条消息是否已经执行过了。Storm的Trident就是基于类似的想法。
当故障恢复需要切换到另一个节点的时候,需要做fencing,以防止被假死节点干扰。
失败后重建状态
为了能在失败后重建状态,一种选择是将状态持久化到远程存储中。另一种方式是本地存储状态,再定期复制。
在某些情况下,可能都不需要复制状态,直接从输入流中重建即可。