Day 5: If You Give A Seed A Fertilizer
Part One
通过seed-to-soil一系列的mapping关系,最终找到最小的location
seeds:79 14 55 13seed-to-soil map:50 98 252 50 48
Explode the mapping
使用递增序列表,将map中的值彻底展开,从而形成一条条具体的mapping关系图
WITH RECURSIVE x(i) AS (
SELECT 1
UNION ALL
SELECT i + 1 from x
),
t(id, n) AS (
select row_number() over () as id, line as n from lance_input
),
seed_to_soil(source, target, cnt) AS (
SELECT arr[2]::bigint, arr[1]::bigint, arr[3]::bigint as cnt
FROM (
SELECT string_to_array(n, ' ') as arr
FROM t
WHERE id > (select id from t where n like 'seed-to-soil map:%')
AND id < (select id from t where n like 'soil-to-fertilizer map:') - 1
) t
),
seed_soil(source, target) AS (
SELECT source + n.i - 1, target + n.i - 1
FROM seed_to_soil m, (select i from x limit (select max(cnt) from seed_to_soil)) n
where m.cnt >= n.i
)
SELECT * FROM seed_soil;
source | target
--------+--------
98 | 50
99 | 51
50 | 52
51 | 53
52 | 54
53 | 55
54 | 56
55 | 57
56 | 58
57 | 59
获取到所有的mapping表后,那直接表之间关联即可
WITH RECURSIVE x(i) AS (
SELECT 1
UNION ALL
SELECT i + 1 from x
),
……
……
其他子查询略
……
……
select min(x) from (
select seed.num, coalesce(humidity_location.target, coalesce(temperature_humidity.target, coalesce(light_temperature.target, coalesce(water_light.target, coalesce(fertilizer_water.target, coalesce(soil_fertilizer.target, coalesce(seed_soil.target, seed.num))))))) as x from seed
LEFT JOIN seed_soil
ON seed.num = seed_soil.source
LEFT JOIN soil_fertilizer
ON coalesce(seed_soil.target, seed.num) = soil_fertilizer.source
LEFT JOIN fertilizer_water
ON coalesce(soil_fertilizer.target, coalesce(seed_soil.target, seed.num)) = fertilizer_water.source
LEFT JOIN water_light
ON coalesce(fertilizer_water.target, coalesce(soil_fertilizer.target, coalesce(seed_soil.target, seed.num))) = water_light.source
LEFT JOIN light_temperature
ON coalesce(water_light.target, coalesce(fertilizer_water.target, coalesce(soil_fertilizer.target, coalesce(seed_soil.target, seed.num)))) = light_temperature.source
LEFT JOIN temperature_humidity
ON coalesce(light_temperature.target, coalesce(water_light.target, coalesce(fertilizer_water.target, coalesce(soil_fertilizer.target, coalesce(seed_soil.target, seed.num))))) = temperature_humidity.source
LEFT JOIN humidity_location
ON coalesce(temperature_humidity.target, coalesce(light_temperature.target, coalesce(water_light.target, coalesce(fertilizer_water.target, coalesce(soil_fertilizer.target, coalesce(seed_soil.target, seed.num)))))) = humidity_location.source) t;
但是经过实际测试,测试结果集比较小的时候,很快就运行出来。但是实际的结果集,数字非常大,从而导致多个大表之间的JOIN,无法在短时间内运行出结果,因此此方案不可行。
Direct join without explode
因此不能展开所有的记录,只能直接关联,关联的条件就是between min and max
SELECT seed.num as origin, coalesce(seed_soil.target + seed.num - seed_soil.source , seed.num) as result
FROM seed
LEFT JOIN seed_soil
ON seed.num between seed_soil.source AND seed_soil.source + seed_soil.cnt - 1
继续与其他表做JOIN,直到得到最终的结果。因此没有展开,因此表JOIN的结果数量不会太大,运行速度也会比较快。最终SQL如下:
WITH t(id, n) AS (
select row_number() over () as id, line as n from lance_input
),
seed(num) AS (
select unnest(string_to_array(trim(split_part(n, ':', 2)), ' ')) :: bigint
from t
where id = 1
),
seed_soil(source, target, cnt) AS (
SELECT arr[2]::bigint, arr[1]::bigint, arr[3]::bigint as cnt
FROM (
SELECT string_to_array(n, ' ') as arr
FROM t
WHERE id > (select id from t where n like 'seed-to-soil map:%')
AND id < (select id from t where n like 'soil-to-fertilizer map:') - 1
) t
),
soil_fertilizer(source, target, cnt) AS (
SELECT arr[2]::bigint, arr[1]::bigint, arr[3]::bigint as cnt
FROM (
SELECT string_to_array(n, ' ') as arr
FROM t
WHERE id > (select id from t where n like 'soil-to-fertilizer map:%')
AND id < (select id from t where n like 'fertilizer-to-water map:') - 1
) t
),
fertilizer_water(source, target, cnt) AS (
SELECT arr[2]::bigint, arr[1]::bigint, arr[3]::bigint as cnt
FROM (
SELECT string_to_array(n, ' ') as arr
FROM t
WHERE id > (select id from t where n like 'fertilizer-to-water map:%')
AND id < (select id from t where n like 'water-to-light map:') - 1
) t
),
water_light(source, target, cnt) AS (
SELECT arr[2]::bigint, arr[1]::bigint, arr[3]::bigint as cnt
FROM (
SELECT string_to_array(n, ' ') as arr
FROM t
WHERE id > (select id from t where n like 'water-to-light map:%')
AND id < (select id from t where n like 'light-to-temperature map:') - 1
) t
),
light_temperature(source, target, cnt) AS (
SELECT arr[2]::bigint, arr[1]::bigint, arr[3]::bigint as cnt
FROM (
SELECT string_to_array(n, ' ') as arr
FROM t
WHERE id > (select id from t where n like 'light-to-temperature map:%')
AND id < (select id from t where n like 'temperature-to-humidity map:') - 1
) t
),
temperature_humidity(source, target, cnt) AS (
SELECT arr[2]::bigint, arr[1]::bigint, arr[3]::bigint as cnt
FROM (
SELECT string_to_array(n, ' ') as arr
FROM t
WHERE id > (select id from t where n like 'temperature-to-humidity map:%')
AND id < (select id from t where n like 'humidity-to-location map:') - 1
) t
),
humidity_location(source, target, cnt) AS (
SELECT arr[2]::bigint, arr[1]::bigint, arr[3]::bigint as cnt
FROM (
SELECT string_to_array(n, ' ') as arr
FROM t
WHERE id > (select id from t where n like 'humidity-to-location map:%')
) t
)
SELECT origin, coalesce(humidity_location.target + result - humidity_location.source, result) as result
FROM (
SELECT origin, coalesce(temperature_humidity.target + result - temperature_humidity.source, result) as result
FROM (
SELECT origin, coalesce(light_temperature.target + result - light_temperature.source, result) as result
FROM (
SELECT origin, coalesce(water_light.target + result - water_light.source, result) as result
FROM (
SELECT origin, coalesce(fertilizer_water.target + result - fertilizer_water.source, result) as result
FROM (
SELECT origin, coalesce(soil_fertilizer.target + result - soil_fertilizer.source, result) as result
FROM (
SELECT seed.num as origin, coalesce(seed_soil.target + seed.num - seed_soil.source , seed.num) as result
FROM seed
LEFT JOIN seed_soil
ON seed.num between seed_soil.source AND seed_soil.source + seed_soil.cnt - 1
) t
LEFT JOIN soil_fertilizer
ON t.result between soil_fertilizer.source AND soil_fertilizer.source + soil_fertilizer.cnt - 1
) t
LEFT JOIN fertilizer_water
ON t.result between fertilizer_water.source AND fertilizer_water.source + fertilizer_water.cnt - 1
) t
LEFT JOIN water_light
ON t.result between water_light.source AND water_light.source + water_light.cnt - 1
) t
LEFT JOIN light_temperature
ON t.result between light_temperature.source AND light_temperature.source + light_temperature.cnt - 1
) t
LEFT JOIN temperature_humidity
ON t.result between temperature_humidity.source AND temperature_humidity.source + temperature_humidity.cnt - 1
) t
LEFT JOIN humidity_location
ON t.result between humidity_location.source AND humidity_location.source + humidity_location.cnt - 1
Part Two
Part Two增加了难度,seed也变成了一堆范围的数字,第一种解法基本也无法短时间内解出。
Range Start Range Size
104847962 3583832
1212568077 114894281
Split range into slices
seed和seed-soil,都变成了range,range之间如何mapping呢?
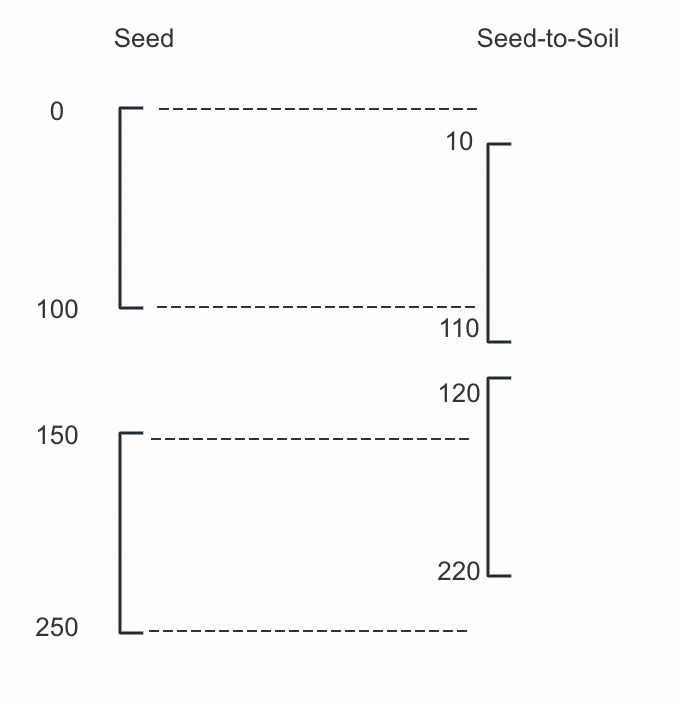
上图中,如果seed的range是[0 – 100],[150 – 250],seed-to-soil的range是[10 – 110],[120 – 220],则对应的mapping记录应该被拆分为:
- [0 – 10],未找到mapping,保持原始值
- [10 – 100],找到mapping,替换为mapping后的值
- [150 – 220],找到mapping,替换为mapping后的值
- [220 – 250],未找到mapping,保持原始值
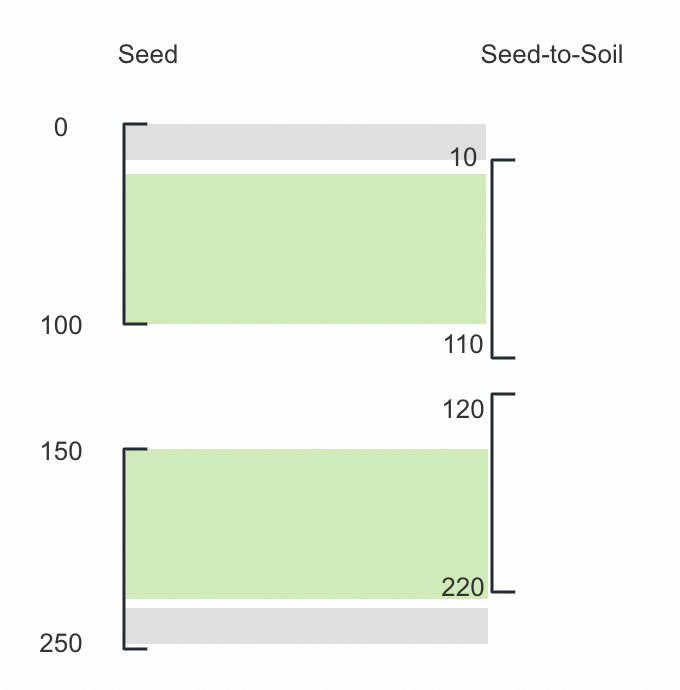
为了方便后续的匹配,需要将seed的range,切分为更细粒度的slice。具体的切分点,就取seed和seed-to-soil两个表中切分点的合集,即[0, 10, 100, 110, 120, 150, 220, 250]
SELECT DISTINCT unnest(s.arr || t.arr) as num
FROM (
SELECT array_agg(start) || array_agg(maxnum) as arr
FROM seed
) s, (
SELECT array_agg(source) || array_agg(maxnum) as arr
FROM humidity_location
) t
ORDER BY 1
切分slice的时候,为了保证不会有重合数据,切分点单独作为一条记录。下文的SQL用到了reduce_dim函数
SELECT reduce_dim(num) as slice
FROM (
SELECT case when next_num is null OR num + 1 = next_num then array[array[num,num]] else array[array[num, num], array[num + 1, next_num - 1]] end as num
FROM (
SELECT num, lead(num) over (order by num) as next_num
FROM (
SELECT DISTINCT unnest(s.arr || t.arr) as num
FROM (
SELECT array_agg(start) || array_agg(maxnum) as arr
FROM seed
) s, (
SELECT array_agg(source) || array_agg(maxnum) as arr
FROM seed_soil
) t
ORDER BY 1
) t
) s
) t;
slice
---------
{50,50}
{51,54}
{55,55}
{56,66}
{67,67}
{68,78}
{79,79}
{80,91}
{92,92}
{93,96}
{97,97}
{98,98}
{99,99}
(13 rows)
获取到slice之后,根据mapping关系,求出mapping后的slice列表
SELECT m.slice,
case when n.source is not null then m.slice[1] - n.source + n.target else m.slice[1] end as start,
case when n.source is not null then m.slice[2] - n.source + n.target else m.slice[2] end as maxnum
FROM soil_slice m LEFT JOIN seed_soil n
ON n.maxnum >= m.slice[2] AND n.source <= m.slice[1]
slice | start | maxnum
-----------------------+-----------+-----------
{0,0} | 533608135 | 533608135
{1,104847961} | 533608136 | 638456096
{104847962,104847962} | 638456097 | 638456097
{104847963,108431792} | 638456098 | 642039927
{108431793,108431793} | 642039928 | 642039928
{108431794,310308286} | 642039929 | 843916421
{310308287,310308287} | 843916422 | 843916422
{310308288,323093895} | 843916423 | 856702030
{323093896,323093896} | 856702031 | 856702031
{323093897,431744149} | 856702032 | 965352284
(10 rows)
Final SQL
每个mapping的result求出后,关联后即可得出原始的range对应的最终result
SELECT seed.start, seed.maxnum, location_slice_result.start as result
FROM seed
JOIN soil_slice_result
ON seed.maxnum >= soil_slice_result.slice[2] AND seed.start <= soil_slice_result.slice[1]
JOIN fertilizer_slice_result
ON soil_slice_result.maxnum >= fertilizer_slice_result.slice[2] AND soil_slice_result.start <= fertilizer_slice_result.slice[1]
JOIN water_slice_result
ON fertilizer_slice_result.maxnum >= water_slice_result.slice[2] AND fertilizer_slice_result.start <= water_slice_result.slice[1]
JOIN light_slice_result
ON water_slice_result.maxnum >= light_slice_result.slice[2] AND water_slice_result.start <= light_slice_result.slice[1]
JOIN temperature_slice_result
ON light_slice_result.maxnum >= temperature_slice_result.slice[2] AND light_slice_result.start <= temperature_slice_result.slice[1]
JOIN humidity_slice_result
ON temperature_slice_result.maxnum >= humidity_slice_result.slice[2] AND temperature_slice_result.start <= humidity_slice_result.slice[1]
JOIN location_slice_result
ON humidity_slice_result.maxnum >= location_slice_result.slice[2] AND humidity_slice_result.start <= location_slice_result.slice[1]