Part One
通过已知的数字,推测左侧的连续#的组合有几种
???.### 1,1,3
.??..??...?##. 1,1,3
?#?#?#?#?#?#?#? 1,3,1,6
????.#...#... 4,1,1
????.######..#####. 1,6,5
?###???????? 3,2,1
穷举所有组合
每个问号,要么是. 要么是#,通过穷举的方法,获取所有可能的组合,并最终判断是否符合右侧的数字
WITH RECURSIVE origin AS (
SELECT row_number() over () as _row, split_part(line, ' ', 1) as records, ('{' || split_part(line, ' ', 2) || '}') :: integer[] as counts
FROM lance_input
), replaced AS (
SELECT _row, records
FROM origin
UNION ALL
SELECT _row, substring(records from 1 for position('?' IN records) - 1) || t.chr || substring(records from position('?' IN records) + 1) as records
FROM replaced, (SELECT unnest('{".", "#"}' :: text[]) as chr) t
WHERE records like '%?%'
), filted AS (
SELECT x._row, x.records, y.counts
FROM replaced x
JOIN (select _row, records, counts, (SELECT SUM(s) FROM UNNEST(counts) s) as total FROM origin) y
ON x._row = y._row
AND length(x.records) - length(replace(x.records, '#', '')) = y.total
AND x.records not like '%?%'
)
SELECT _row, records, counts, array_agg(length(elem) order by nr)
FROM (
SELECT _row, a.elem, a.nr, records, counts
FROM filted, unnest(array_remove(string_to_array(records, '.'), '')) WITH ORDINALITY a(elem, nr)
) t
GROUP BY _row, records, counts
HAVING array_agg(length(elem) order by nr) = counts;
1000条的测试集,耗时20多秒,性能比较差。归根结底,所有的组合记录数还是非常多的,且最后要判断是否满足右侧的条件,因此这种方式是比较笨的。
# result
----------------------------------------------------------------
1000 | #.######..#### | {1,6,4} | {1,6,4}
1000 | #..######.#### | {1,6,4} | {1,6,4}
1000 | .#.######.#### | {1,6,4} | {1,6,4}
(7169 rows)
Time: 29844.795 ms (00:29.845)
及时评估有效性
其实每一步迭代后,虽然?没有被全部替换掉,但还是可以判断当前已有的字符串是否有效。
???.### 1,1,3 以此为例
#??.### 有效
##?.### 无效
获取?左边的字符串,并根据.进行切分,根据下述规则进行判定
- 如果是.结尾,则已有的#的长度组合,需要是总长度组合的子集,比如[1, 1] ∈ [1, 1, 3]
- 如果是#结尾,则已有的#的组合还未结束,最后一个长度不能超过,比如[1, 2] ∈ [1, 3, 3]
使用SQL来表达
CASE WHEN left_char like '%.' THEN subarray(counts, 1, #left_array) = left_array
WHEN left_char like '%#' THEN
CASE WHEN #left_array = 1 THEN left_array[1] <= counts[1]
ELSE subarray(counts, 1, (#left_array)- 1) = subarray(left_array, 1, (#left_array) - 1)
AND left_array[#left_array] <= counts[#left_array]
END
END
因此每次迭代后,都会核验当前字符串是否有效,从而达到快速过滤的作用,减少总体的时间消耗。
WITH RECURSIVE origin AS (
SELECT row_number() over () as _row, split_part(line, ' ', 1) as records, ('{' || split_part(line, ' ', 2) || '}') :: integer[] as counts
FROM lance_input
), replaced AS (
SELECT _row, records, counts, true as valid
FROM origin
UNION ALL
SELECT _row, records, counts,
CASE WHEN left_char not like '%#%' then true
ELSE
CASE WHEN left_char like '%.' THEN subarray(counts, 1, #left_array) = left_array
WHEN left_char like '%#' THEN
CASE WHEN #left_array = 1 THEN left_array[1] <= counts[1]
ELSE subarray(counts, 1, (#left_array)- 1) = subarray(left_array, 1, (#left_array) - 1)
AND left_array[#left_array] <= counts[#left_array]
END
END
END as valid
FROM (
SELECT _row, records, counts, left_char, array_agg(length(elem) order by nr) as left_array
FROM (
SELECT _row, records, counts, case when position('?' IN records) > 0 then substring(records from 1 for position('?' IN records) - 1) else records end as left_char
FROM (
SELECT _row,
substring(records from 1 for position('?' IN records) - 1) || t.chr || substring(records from position('?' IN records) + 1) as records,
counts
FROM replaced, (SELECT unnest('{".", "#"}' :: text[]) as chr) t
WHERE records like '%?%' AND valid
) s
) t
LEFT JOIN unnest(array_remove(string_to_array(left_char, '.'), '')) WITH ORDINALITY a(elem, nr)
ON TRUE
GROUP BY _row, records, counts, left_char
) s
)
SELECT _row, records, counts, array_agg(length(elem) order by nr)
FROM (
SELECT _row, a.elem, a.nr, records, counts
FROM replaced, unnest(array_remove(string_to_array(records, '.'), '')) WITH ORDINALITY a(elem, nr)
WHERE records not like '%?%' AND valid
) t
GROUP BY _row, records, counts
HAVING array_agg(length(elem) order by nr) = counts;
优化后,时间缩短至2秒多
# result
----------------------------------------------------------------
1000 | #.######..#### | {1,6,4} | {1,6,4}
1000 | #..######.#### | {1,6,4} | {1,6,4}
1000 | .#.######.#### | {1,6,4} | {1,6,4}
(7169 rows)
Time: 2897.770 ms (00:02.898)
Part Two
第二关增加了难度,长度增加到了之前的5倍,且中间夹杂了4个任意字符
xxx -> xxx?xxx?xxx?xxx?xxx
如果还是使用第一关的方法,复杂度会大大增加,在短时间内基本无法运行出来,需要使用更加便捷的方法。
分段统计 ❌
下意识的一个方法,就是切分为5段,分别进行统计。再将每段的结果进行JOIN后,去除掉无效的记录(首尾都是#导致与右侧长度不匹配),即是最终的结果。
???.### 1,1,3 仍然以此为例
扩展5倍后变成了
???.###????.###????.###????.###????.### 1,1,3,1,1,3,1,1,3,1,1,3,1,1,3
切分为5段后
???.### | ????.### | ????.### | ????.### | ????.###
有效的结果
#.#.### .#.#.###
无效的结果
#.#.### #.#..###
几段结果JOIN后,排除掉无效结果,从而得出组合后的组合数
-------------------------------------------------------------------------
postgres(# SELECT t2._row, t2.records
postgres(# FROM first t1
postgres(# JOIN second t2
postgres(# ON t1._row = t2._row
postgres(# AND NOT (t1.records like '%#' AND t2.records like '#%')
不过得出的结果,比正确答案少了很多。经过分析,这种方法其实是有漏洞的,原因如下
以简单的 ????# 1,1为例,扩展后变成了
????# | ?????# 1,1,1,1
....# | .#.#.#,这种组合虽然跨越了分界线,但是其实总体看来也是有效的。
Dynamic Programming
我们需要使用动态规划来解决此类问题,类似于背包问题,建立m*n的矩阵,矩阵的每个方格的结果都会依赖上一步的结果。当矩阵的方格都填满后,结果自然就有了。
如下图所示,定义S为字符串,L为长度数组。m为{1,2,…,len(S)},n为{1,2,…,len(L)},则(m,n)的数字就是有多少种组合满足(m,n)的限定条件。
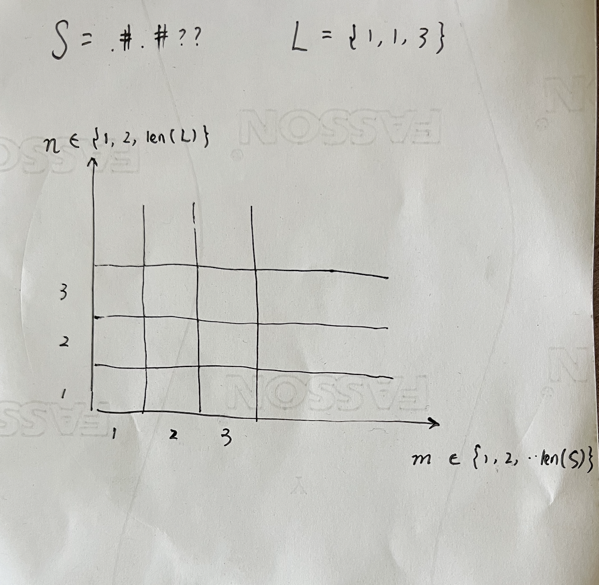
仍然以???.### 1,1,3为例
(m,n) = (2,1)的时候,就是指"??"满足{1}有几种组合?应该是有两种,.#与.#。
(m,n) = (2,2)的时候,就是指"??"满足{1,1}有几种组合?应该是有0种,不可能出现。
(m,n) = (3,2)的时候,就是指"???"满足{1,1}有几种组合?应该是有1种,#.#。
二维 -> 三维
但是二维数组是否足够?是否足以计算出最终的结果?
仍然以???.### 1,1,3为例
(m,n) = (5,3)的时候,就是指"???.#"满足{1,1,3}有几种组合?0
(m,n) = (6,3)的时候,就是指"???.##"满足{1,1,3}有几种组合?0
(m,n) = (7,3)的时候,就是指"???.###"满足{1,1,3}有几种组合?1
从上面的例子中,可以看到在长度未满足的时候,结果大部分为0,导致这个结果并不能给后续的计算带来帮助。因此m的长度是平滑变化,而n的变化就不是平滑的,从{1,1}直接变化到了{1,1,3}。我们期望是这个变化也是平滑的,从{1,1} -> {1,1,0} -> {1,1,1} -> {1,1,2} -> {1,1,3}。因此需要再增加一个维度k,从而
m: 1 ~ len(S)
n: 1 ~ len(L)
k: 0 ~ L[n+1]
运算规则
接下来分析如何通过前面的结果,计算当前的结果。
当前位置为(m,n,k)
-----------------------------如果当前字符是.-----------------------------
分两种情况:
1. 上一个字符是#时
matrix[m,n,k] = matrix[m-1,n-1,L[n-1]]
2. 上一个字符时.时
matrix[m,n,k] = matrix[m-1, n, 0]
因此,合2为1
matrix[m,n,k] = matrix[m-1,n-1,L[n-1]] + matrix[m-1, n, 0]
-----------------------------如果当前字符是#-----------------------------
组合方式不变,继承上一个字符的结果
matrix[m,n,k] = matrix[m-1,n,k-1]
-----------------------------如果当前字符是?-----------------------------
分两种情况,将上面两种结果加起来即可
matrix[m,n,k] = matrix[m-1,n,k-1] + matrix[m-1,n-1,L[n-1]] + matrix[m-1, n, 0]
这里需要注意的是,我们最终需要的所有可能的组合方式。因此我们需要的是最后一位是#/.两种情况的全部集合。但是按照上述的算法,???????.??? 1,3这个例子中,最后一个位置是(m=11, n=2, k=3),那么结果仅包含了最后一位是#的情况,少了最后一位是.的场景。因此我们在字符串最后强行加一个.,并且将{1,3}扩展为{1,3,0},这样最后一个位置就是(m=12, n=3, k=0)。
(m=12, n=3, k=0)
= (m=11, n=2, k=3)+(m=11, n=3, k=0)
= 上一个字符是# + 上一个字符是.
最终SQL
首先初始化m * n * k的矩阵,count全部初始化为0。为了节省空间,仅保留了counts,没有保留records。
CREATE TABLE matrix AS
WITH RECURSIVE origin AS (
SELECT _row, length(records || '?' || records || '?' || records || '?' || records || '?' || records || '.') as records,
counts + counts + counts + counts + counts + 0 as counts
FROM (
SELECT row_number() over () as _row, split_part(line, ' ', 1) as records, ('{' || split_part(line, ' ', 2) || '}') :: integer[] as counts
FROM lance_input
) t
), seq AS (
SELECT 1 as id
UNION ALL
SELECT id + 1 as id
FROM seq
), init_arr AS (
SELECT origin.*, m.id as m, n.id as n, k.id - 1 as k, 0 as cnt
FROM origin,
(select id from seq limit 105) m,
(select id from seq limit 31) n,
(select id from seq limit 32) k
WHERE origin.records >= m.id
AND #origin.counts >= n.id
AND origin.counts[n.id] + 1 >= k.id
)
SELECT _row, counts, m, n, k, cnt::bigint from init_arr;
CREATE TABLE origin AS
SELECT _row, records || '?' || records || '?' || records || '?' || records || '?' || records || '.' as records,
counts + counts + counts + counts + counts + 0 as counts
FROM (
SELECT row_number() over () as _row, split_part(line, ' ', 1) as records, ('{' || split_part(line, ' ', 2) || '}') :: integer[] as counts
FROM lance_input
) t
create index idx_matrix ON matrix(_row, m, n, k);
然后通过一个function来进行遍历,逐步更新matrix中的内容,从而找出最终位置的结果。
CREATE OR REPLACE FUNCTION dp(row_id INTEGER)
RETURNS BIGINT AS $$
DECLARE
full_str VARCHAR;
arr_len INTEGER[];
current_char VARCHAR;
current_cnt BIGINT := 0;
dot_cnt BIGINT := 0;
pound_cnt BIGINT := 0;
BEGIN
full_str := (SELECT records FROM origin WHERE _row = row_id LIMIT 1);
arr_len := (SELECT counts FROM origin WHERE _row = row_id LIMIT 1);
FOR i IN 1..length(full_str) LOOP
current_char := substring(full_str from i for 1);
FOR j IN 1..(#arr_len) LOOP
FOR kk IN 0..arr_len[j] LOOP
current_cnt := 0;
dot_cnt := 0;
pound_cnt := 0;
IF i = 1 AND j = 1 THEN
IF current_char = '#' AND kk = 1 THEN
current_cnt := 1;
END IF;
IF current_char = '.' AND kk = 0 THEN
current_cnt := 1;
END IF;
IF current_char = '?' AND kk IN (0, 1) THEN
current_cnt := 1;
END IF;
ELSE
IF kk > 0 THEN
pound_cnt := coalesce((SELECT cnt FROM matrix where matrix._row = row_id AND matrix.m = i - 1 AND matrix.n = j AND matrix.k = kk - 1), 0);
END IF;
IF kk = 0 THEN
dot_cnt := coalesce((SELECT cnt FROM matrix where matrix._row = row_id AND matrix.m = i - 1 AND matrix.n = j - 1 AND matrix.k = counts[j-1]), 0);
dot_cnt := dot_cnt + coalesce((SELECT cnt FROM matrix where matrix._row = row_id AND matrix.m = i - 1 AND matrix.n = j AND matrix.k = 0), 0);
END IF;
IF current_char = '.' THEN
current_cnt := dot_cnt;
END IF;
IF current_char = '#' THEN
current_cnt := pound_cnt;
END IF;
IF current_char = '?' THEN
current_cnt := pound_cnt + dot_cnt;
END IF;
END IF;
UPDATE matrix SET cnt = current_cnt WHERE matrix._row = row_id AND matrix.m = i AND matrix.n = j AND matrix.k = kk;
END LOOP;
END LOOP;
END LOOP;
RETURN (SELECT cnt FROM matrix WHERE matrix._row = row_id AND matrix.m = length(full_str) AND matrix.n = (#arr_len) AND matrix.k = 0);
END;
$$ LANGUAGE plpgsql;
最终结果如下:
postgres=# select sum(dp(_row::integer)) from (select distinct _row from matrix) t;
sum
---------------
1738259948652
(1 row)