The Machine Learning Landscapes
为何用Machine Learning?
替代传统规则
以垃圾邮件过滤举例,传统编程方式会不断新增规则,规则一般都是根据邮件中包含的关键词,比如“credit card”,“free”等。最后关键词列表会不断膨胀,导致规则难以维护。另一方面,垃圾邮件的发送方也会不断尝试使用新的文案,之前的规则就会失效,就需要持续增加关键词,维护成本较高。
而机器学习的方式,通过学习用户打标的垃圾邮件,自动识别出相应的规则,也就是关键词列表,无需太多的人工干预。
传统方式很难解决的问题
比如语音识别,不同语言不同口音,再加上每个人的发音各不相同,使用传统方式来识别语音的难度极大,所以目前最好的方式,仍然是根据成千上万的例子(有识别结果的语音)自我学习。
模式识别
机器学习自动识别出的规则,反而能够帮助人类发现潜在的一些规则。还是以垃圾邮件识别举例,机器学习识别出来的规则,同样是一些关键词或者关键词的组合,这些能够反映出时下的一些趋势。通过机器学习从大量数据中发掘潜在规律的,称之为数据挖掘(data mining)。
总结
机器学习的优势体现在:
- 需要大量人工维护的规则
- 传统方式无法解决的难题,比如语音识别、围棋
- 不稳定的环境中,机器学习更易适应新数据
- 从大量数据中获取洞悉
Machine Learning的分类
监督学习与无监督学习
根据训练期间是否监督以及监督的程度,可以分为监督学习、无监督学习、半监督学习、强化学习。
监督学习(Supervisd Learning)
在监督学习中,训练数据需要标签。监督学习主要有两大类任务。
- 分类(Classification)
- 回归(Regression)
一些重要的监督学习算法,如:
- KNN(k-Nearest Neighbors)
- Linear Regression
- Logistic Regression
- SVM(Support Vector Machines)
- Decision Tree and Random Forests
- Neural networks
无监督学习(Unsupervised Learning)
在无监督学习中,训练数据没有标签,只能自我学习。
主要的算法如下:
- 聚类(Clustering)
- k-Means
- Hierarchical Cluster Analysis(HCA)
- Expectation Maximization
- 可视化及降维(Visualization and dimensionality reduction)
- 主成分分析(Principal Component Analysis, PCA)
- Kernel PCA
- Locally-Linear Embedding(LLE)
- t-distributed Stochastic Neighbor Embedding(t-SNE)
- 关联规则学习(Association rule learning)
- Apriori
- Eclat
半监督学习(Semisupervised Learning)
无监督学习算法与监督学习算法的结合,比如Google Photos,先通过聚类算法将照片人物分组,用户打标之后,就可以通过算法给所有的照片进行打标,方便照片搜索。
强化学习(Reinforcement Learning)
在学习过程中,存在一个agent,通过不断观察环境,选择策略行动后,得到相应的奖励或者惩罚。最终通过不断的尝试后,发现最佳的策略(policy)。比如Deepmind的AlphaGo
批量学习与在线学习
按照是否可以增量学习实时流数据,分为批量学习和在线学习。
批量学习(Batch Learning)
批量学习,只能一次训练全部的数据,需要消耗大量的时间和资源,也被称为离线学习(offline learning)。如果想训练新的数据,则需要从头开始重新训练一个新版本。
在线学习(Online Learning)
在线学习中,可以逐个喂入训练数据,或者小批量(mini-batches)的方式,因此很适合那些流式输入的系统,比如股票系统。
训练完的数据可以丢弃掉,从而节省空间资源。由于可以分批训练数据,因此机器的内存不需要装载所有的数据(称为out-of-core learning)。
在线训练的一个重要参数就是系统多快地学习好新的数据,称为学习率(learning rate)。如果学习率很高,那么学习的速度越快,可是忘记旧知识的速度也越快。相反,学习率设置低的话,系统会有一定的“惯性”,也就是说虽然学习速度慢,但是也不会被新知识很快覆盖。
在线学习的一个挑战,就是如果有脏数据进来,则系统表现会大幅下降。如果是一个在线系统,则用户很快会注意到。因此,需要有相应的系统性能监控,以及输入异常数据的监控。
Instance-Based vs Model-Based
根据如何泛化(也就是根据训练集训练好后,如何应用到新的数据上),还可以分类为instanced-based与model-based。
Instance-based Learning
还以垃圾邮件打标为例,最直接的做法,就是记住已经打标好的邮件的内容,然后通过计算目标邮件的相似度,来判断邮件是否为垃圾邮件。相似度的计算,可以是统计重复关键词的次数等方式。
Model-based Learning
另一种泛化的方式,就是通过训练计算出一个模型,通过这个模型去预测新的数据。
书中的例子,就是幸福指数与人均GDP的关系。根据样本,大概可以看出是一个线性关系,因此决定选择一个线性模型(该表称之为model selection)
life_satisfication = θ0 + θ1 * GDP_per_capita
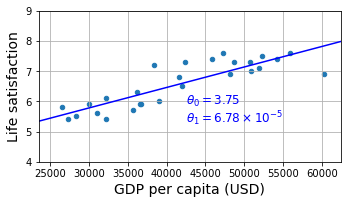
要确定模型的参数θ0与θ1 ,就需要有评估的方式。要么定义一个适配函数(fitness function / utility function)来衡量模型的表现有多好,要么定义一个损失函数(loss function)来衡量模型表现有多差。对于线性回归的场景,一般都是用损失函数,来计算出预测结果与实际结果的差异,目标就是尽量减少这个差异。
还有一种预测方式,就是instance-based learning。通过找出样本中最靠近目标国家的三个国家,计算他们的平均值,就是目标的预测值。这种方式就是kNN(这里neighbor数量取3)。
总体来说,分为四个步骤:
- 研究样本数据
- 选择一个适合的模型(model selection)
- 基于训练集的模型训练(通过损失函数找到最优模型参数)
- 将模型应用到新的数据上(推理 / inference)
机器学习的主要挑战
挑战主要有bad data和bad algorithm
Data – 训练集的数量
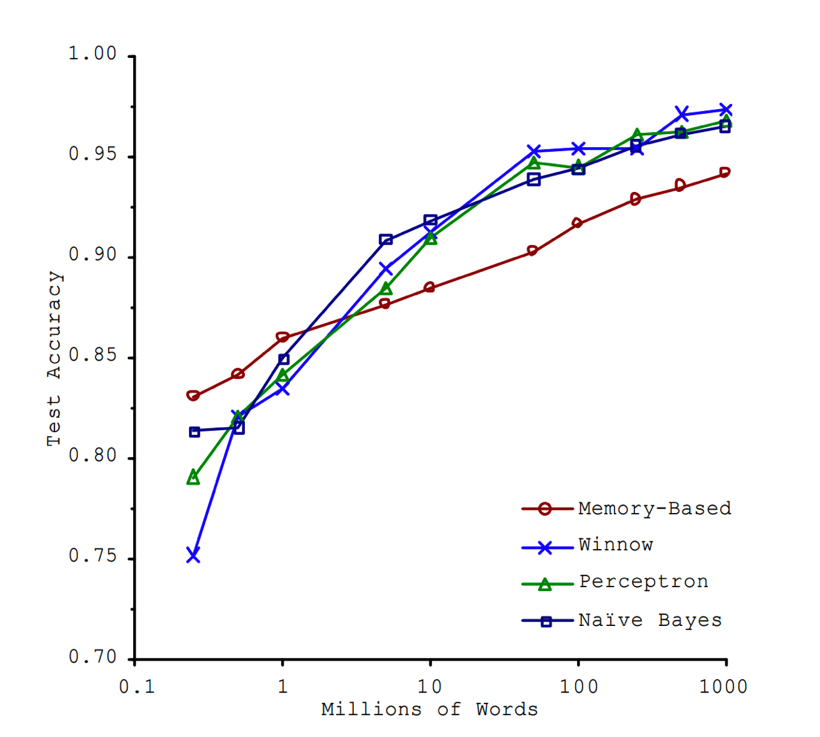
The Unreasonble Effectiveness of Data论文显示,即使是不同的算法,只要有足够的训练集,就可以达到差不多相同的准确度。作者也提到,与其花费精力开发算法,也许找到足够的训练集也能达到相同的效果。
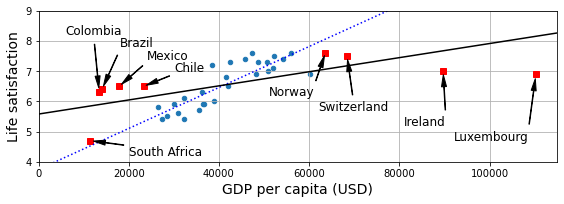
Data – 训练集的代表性
如果训练集不够代表性,那么训练出来的模型也是不准确的。以下图为例,如果一开始没有高GDP的几个样本数据,那么训练出来的模型是虚线,与真实差距较大。只有当红色的样本加入后,训练出的模型才更准确。这种样本不够代表性,也被称为样本偏差(sampling bias)。
Data – 训练集的数据质量
如果训练集数据满是错误、噪音、异常值,那么系统就很难表现良好。所以,数据科学家都会耗费很大的精力在数据的清洗上面:
- 如果某些样本明显是异常值,要么直接丢弃掉,要么手动修复下数据。
- 如果某些样本的某些特征值缺失,比如年龄字段。对于这种情况,可以直接拿年龄中位数填充,或者训练一个不依赖年龄的模型。
Data – 特征的相关性
老话说:Garbage in,garbage out。需要挑选出最相关的特征,称之为特征工程(feature enginerring)。
- 特征选择(feature selection):从已有特征中挑选出最有用的特征。
- 特征提取(feature extraction):将已有特征组合为更有用的特征,比如之前的PCA等算法。
- 从新的数据中提取新的特征
Algorithm – 过拟合
机器学习中,当模型在训练集上表现良好,但是并不能泛化到其他数据上,称之为过拟合(overfitting)。比如下面这幅图,就是采用了多项式(最高10次项)模型。
poly = preprocessing.PolynomialFeatures(degree=10, include_bias=False)
scaler = preprocessing.StandardScaler()
lin_reg2 = linear_model.LinearRegression()
pipeline_reg = pipeline.Pipeline([
('poly', poly),
('scal', scaler),
('lin', lin_reg2)])
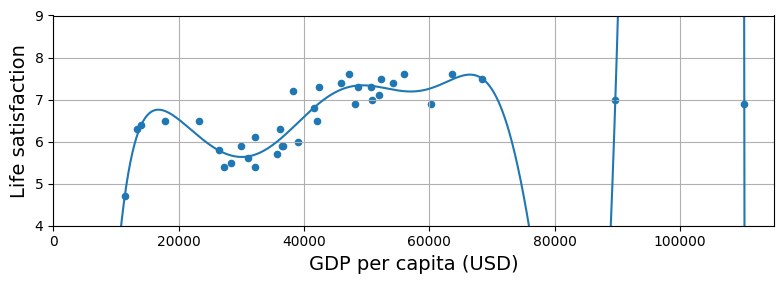
虽然上面的模型能够完美拟合测试集中的每个样本,但是并不能将模型用于预测。
过拟合一般是由于模型相对于训练集来说太过复杂了,可能的解决方式就是:
- 简化模型,比如不要使用高次项的多项式模型,而是采用简单的线性拟合
- 准备更多的训练数据
- 减少训练集中的噪音(修复数据集中的异常和错误)
正则化(Regularization)
为了解决过拟合,让模型更加简单,不能有很多的参数。还是以之前的线性模型为例:θ0 + θ1 * GDP_per_capita。如果仅有θ0一个参数,就会变成水平直线,所以还是要加上第二个参数θ1 。但是为了避免引入第二个参数导致的过拟合,因此需要一个正则化(Regularization)的过程,用于限制参数的大小。
如下图所示,正则化的虚线相比于未正则化的虚线,更能拟合全部的样本。
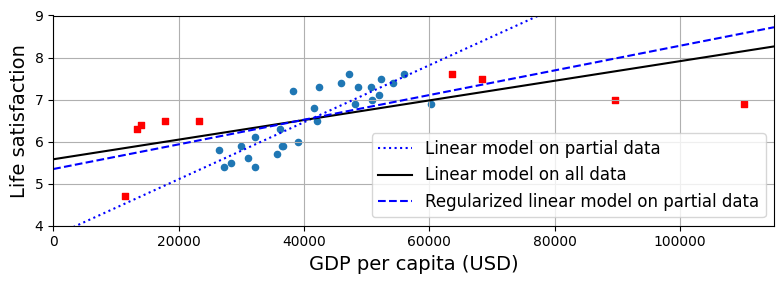
这个正则化的度,是由一个hyperparameter来控制的。hyperparameter越大,会导致正则化限制的越多,会导致参数过小,因此这个参数的调优特别重要。
正则化的原理
损失函数定义为目标结果与实际结果的差异

模型训练的过程,其实是寻找全局损失函数的最小化

正则化就是为了对抗过拟合,特意向损失函数中加入描述模型复杂程度的正则项Ω(F),从而让寻找最小化的公式变成了

Algorithm – 欠拟合
过拟合的反面,就是欠拟合(underfitting),原因就是模型过于简单,解决方法有以下几种
- 选择更强大的模型,增加更多的参数
- 通过特征工程,选择更好的特征
- 减少对模型的限制(比如减少正则化的hyperparameter)
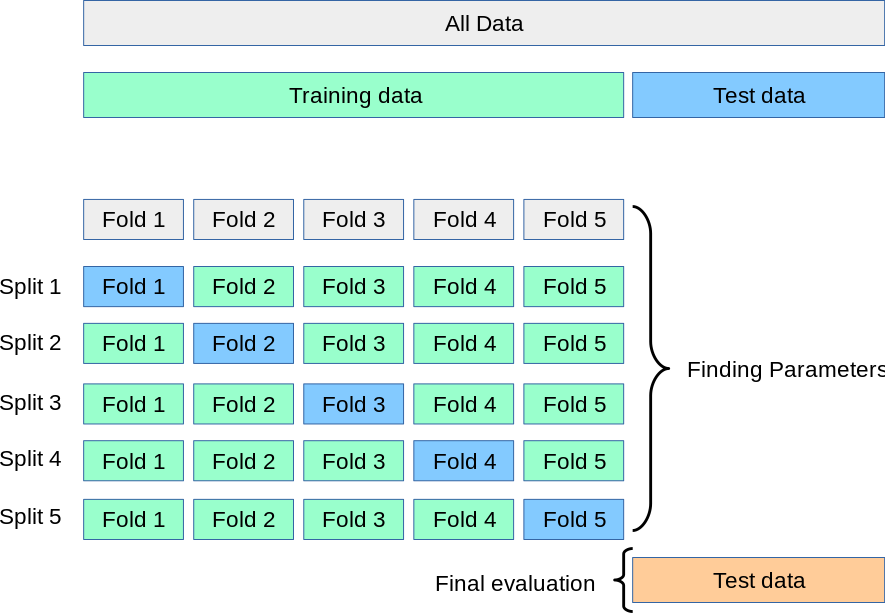
测试与验证
需要将样本分为训练集(training set)与测试集(test set),一般的经验比例是80%:20%。通常的做法就是通过训练集训练模型后,然后将模型用于测试集,并评估模型的表现。模型在测试集上的错误率,又被称为泛化误差(generalization error,out-of-sample error),这个误差就是评估模型表现的主要指标。
但是会遇到测试集上表现良好,但是投入生产后表现不佳。这是因为泛化误差,针对的永远是测试集,所以模型的参数,其实是在测试集上的最优参数,并不一定是实际的最优。
一个可行的解决方法,就是增加一个新的验证集(validation set)。做法就变成了:
- 基于训练集(training set)训练模型
- 基于验证集(validation set)统计误差,从而挑选出合适的模型与超参数
- 将模型运行于测试集(test set),评估出误差
还有一种做法,就是交叉验证(cross-validation)。这里就无需用到验证集了,是将训练集分拆成多个子集,每个模型都是使用其中若干个子集,并用剩余的样本做验证,具体如图所示